🚓 Policy Gradient relies on gradient descent to optimize the policy, which (at least in the world of 🎓 Supervised Learning) is stable and usually converges to some optimum. However, the key issue with simply using gradient descent is that unlike supervised problems that have a fixed data distribution, the data distribution our policy gradient learns from is itself dependent on the policy.
This means that our gradient update step affects the data distribution of our next time step. However, since our gradient was estimated using our current data distribution, it would be inaccurate for a new data distribution that’s different from the current one; that is, if we make a big update to our policy that lands us in a drastically different data distribution, the training process will be unstable.
Theory
To formalize this problem, we can consider policy gradients as a “soft” version of ♻️ Policy Iteration: rather than directly setting
In the context of policy iteration, we can view the gradient step as finding some new parameters
If we let
Observe that maximizing this quantity is the same goal as policy iteration, where we set a new policy
Expanding the right hand side and applying 🪆 Importance Sampling, we have
Unfortunately, the first expectation samples from the distribution defined by
Bounding Mismatch
In order to approximate
we need to bound the difference between
Formally, we define “closeness” between the policies as
where the left hand side is the 👟 Total Variation Distance between the two distributions. It can be shown that given this condition, we can bound
Given this bound on the state distributions, we can then lower bound the true expectation by
where
Constrained Policy Updates
Our goal now is to optimize our approximation while ensuring the closeness between our old and new policies. The total variation distance is upper bounded by ✂️ KL Divergence, and we’ll use the KL constraint
for mathematical convenience.
Note that if we compare this constraint with our original policy gradient update, which can be viewed as
our new constraint considers the distributions defined by
The natural policy gradient solves our objective
with the 🌱 Natural Gradient. We first note that the gradient of our objective is
and to find the gradient at our current policy, we plug in
Following the general natural gradient, we approximate our constraint
where
where
if we decide to set
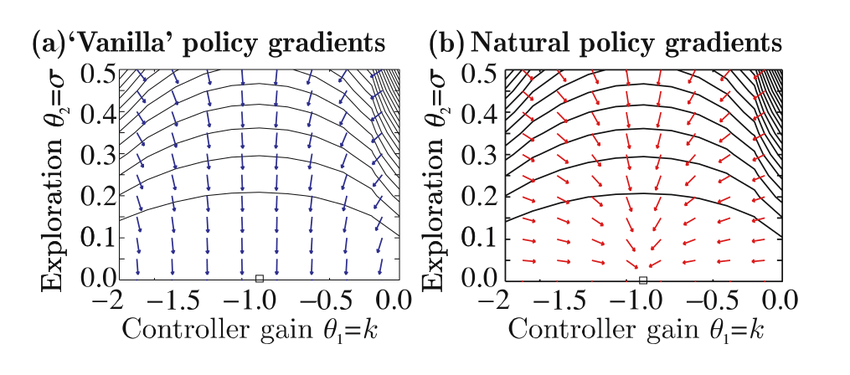
The result of changing the constraint is illustrated below: