BYOL (bootstrap your own latent) is a 🪩 Representation Learning method that uses two neural networks that learn from each other rather than a contrastive objective. We have online and target networks; the former will be constantly updated, and the latter is a time-lagged version of the former.
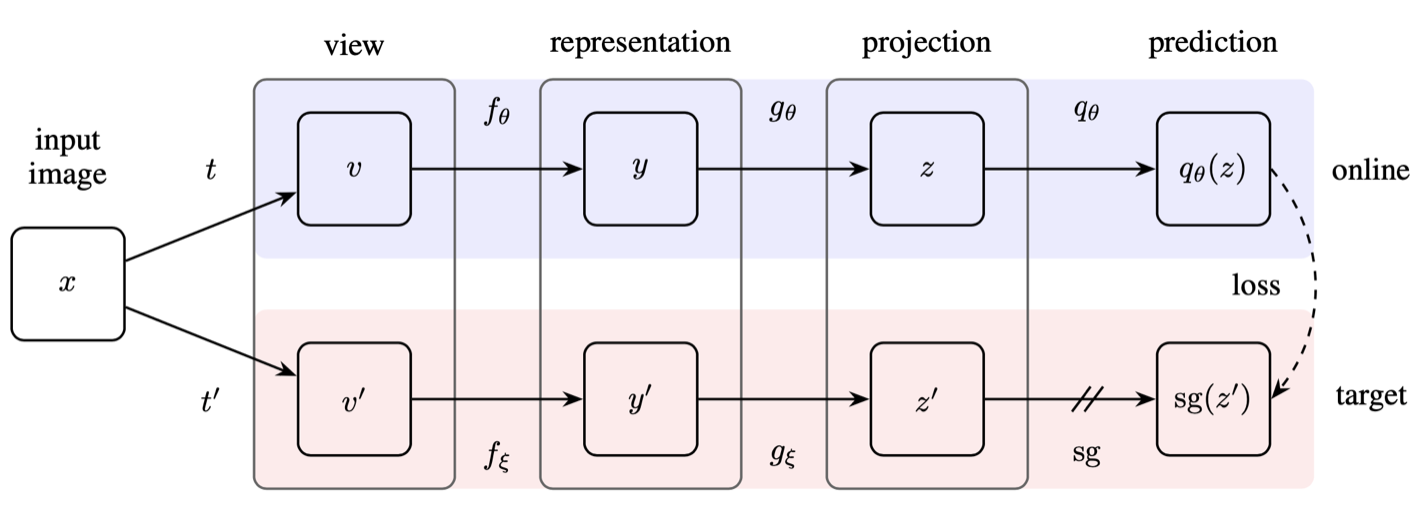
The online network, parameterized by
A simple pretext task for representation learning would be to learn some representation and projection that predicts the output of another randomly initialized and fixed network. This doesn’t result in good representations, however, so BYOL slightly modifies this objective: instead of a random target, we’ll have our online network predict the projection (output) of the lagging target network—hence the “bootstrapping” in its name.
Formally, we have the following steps:
- Get a sample image
and form two views and via augmentations and . - Get a representation
and projection from the online network and similarly and from the target network. - Output a prediction
for , and define the loss between normalized and as
- Compute the “mirrored” loss
by feeding into the online network and into the target and performing the same steps above, then minimize this symmetric loss only for the online network,
- Finally, update the target
with Polyak averaging.
Theoretically, BYOL’s framework is susceptible to collapse since both networks can predict a constant for all inputs. However, one insight into its empirical performance is that while the collapsed presentation is the minimum of our loss, the Polyak averaging updates for