PointNet is an architecture that operates on unordered sets of points; its key design is permutation invariance—changing the ordering of the input doesn’t affect the output. Moreover, additional transform modules also account for geometric transformations.
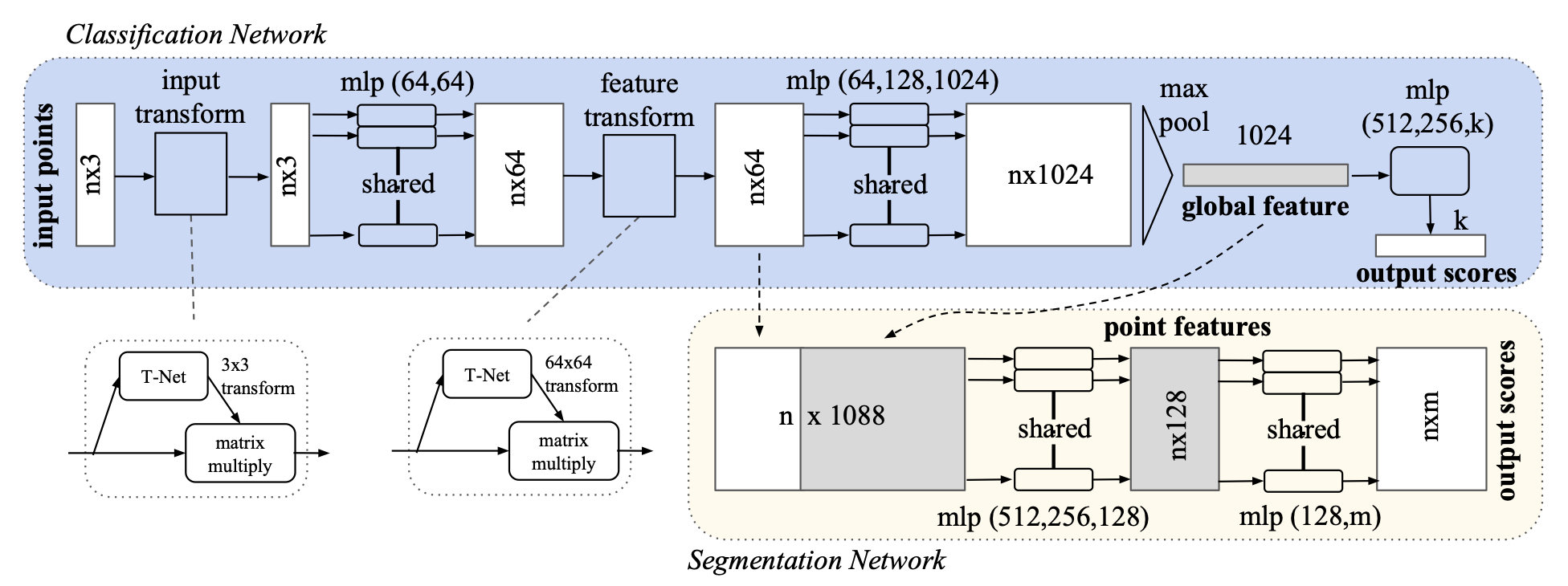
The main backbone of the network (in blue) takes
For classification, we can pass the global features to a final MLP that computes class probabilities. For semantic segmentation, we need to incorporate local per-point feature information as well (in yellow), so we concatenate the global features to point features and process it with more per-point MLPs that consider both global and local information.
The input transform at the start is a smaller network that generates a
Key Points
One property of the max pool is robustness. For a max pooling layer of dimension
The network is similarly robust to some level of input noise where adding additional points outside of the critical set doesn’t affect the output.
We can visualize the critical points below; the first row is our input, second is the critical set, and third is the largest possible input that results in the same input.
