Autoregressive models parameterize the joint distribution
is the random variables with index less than
Info
The “autoregressive” name comes from time-series models that predict outcomes based on past observations. In this setting,
is analogous to the th time step.
If we parameterize
where
Info
For non-binary discrete or continuous random variables, we can predict softmax for the former and parameterized distributions (mixture of Gaussians, for example) for the latter.
Since we restricted our function to a fixed number of parameters, we’re limiting the expressiveness of our model. This is the tradeoff we get using this computationally-feasible representation.
Variants
FVSBN
If we let our function we a linear combination of the inputs with a non-linearity,
with
To increase the expressiveness, we can simply add more hidden layers and use a 🕸️ Multilayer Perceptron for our function instead.
NADE
Neural autoregressive density estimator (NADE) is an alternative method that shares some MLP parameters across conditionals, so we have the following:
The first layer of computations uses shared weights, and the second uses separate weights. This reduces the total number of parameters to
MADE
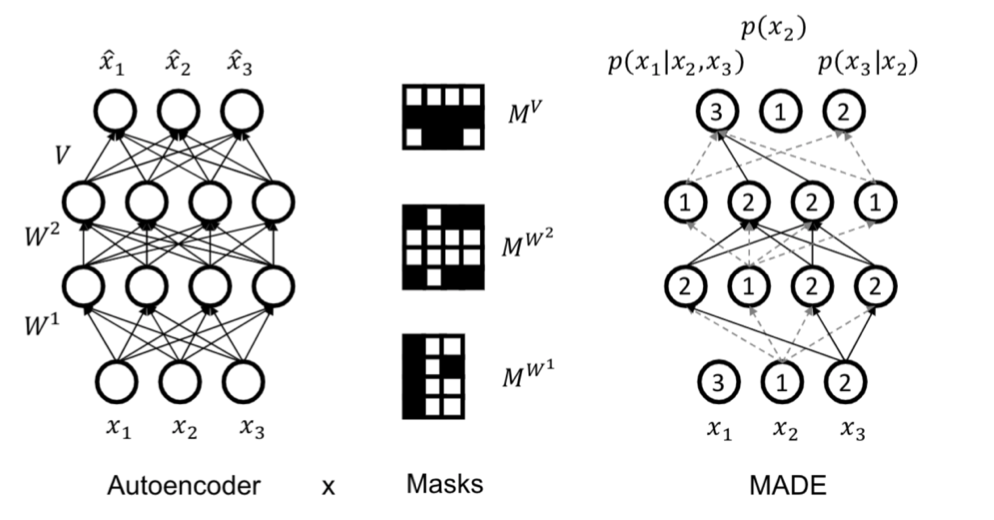
Masked autoencoder for distribution estimation (MADE) combines the autoregressive property with an 🧬 Autoencoder, which aims to reconstruct our input
However, by the autoregressive property, a standard architecture doesn’t work because all outputs require all inputs. MADE sets a certain order for the input dimensions and masks out certain paths in the autoencoder to enforce the autoregressive property; that is, in MADE,
Recurrence
To model
Optimization
Autoregressive models benefit from explicitly modeling
Since
With an analytical form for
where
Sampling
To sample from our learned distribution