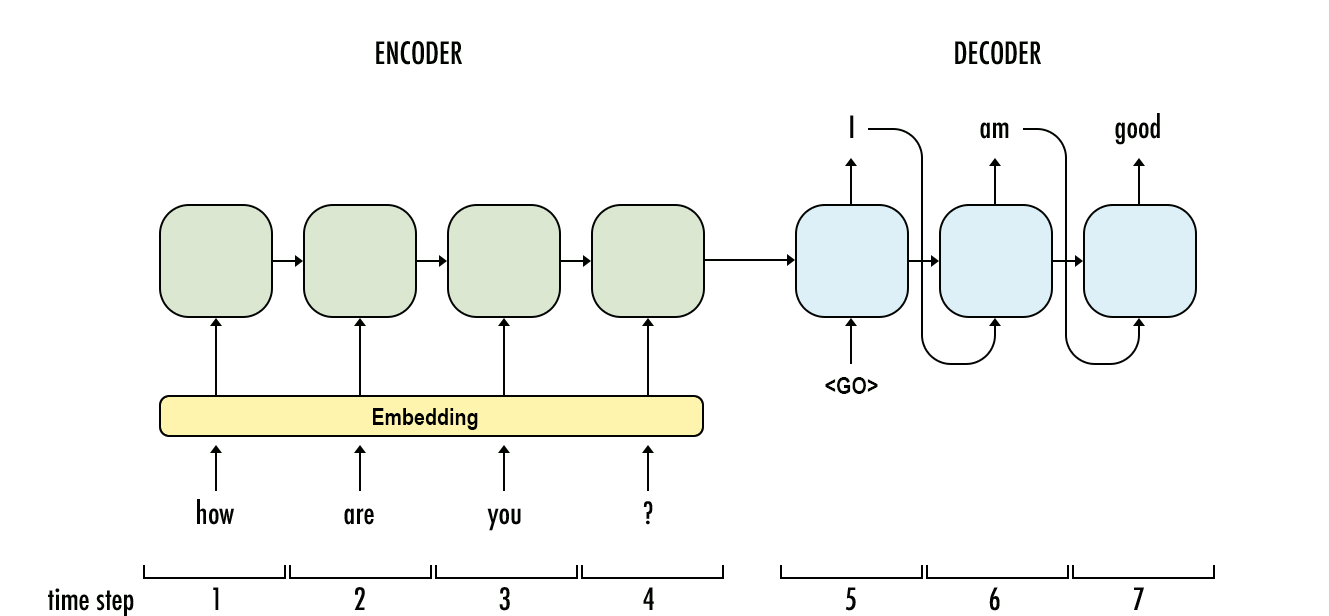
Sequence-to-sequence models are used for translation, outputting a sequence from an input sequence. It uses 💬 Recurrent Neural Networks, 🎥 Long Short-Term Memory, or ⛩️ Gated Recurrent Units to encode the sequence into a hidden state and then decode it into another sequence.
The core idea is that the encoder’s output summarizes the entire sequence, and the decoder can use this summary to generate a response. This architecture is pictured below.
Attention
One core problem with the standard Seq2Seq approach is that it struggles with long sequences as information earlier in the sequence tend to get lost. The🚨 Attention mechanism addresses this weakness by passing on the hidden states as well.
We add a step between the encoder and decoder that utilizes all hidden states from the encoder to figure out which hidden states are most relevant to each decoding time-step. In this application, the query is analogous to the previous decoder output
Then, instead of passing the encoder output directly to the decoder, we instead compute a weighted average of all hidden encoder states at each decoder time-step. At time
- For each encoder hidden state
and previous decoder output , use a feed-forward neural network to compute the th alignment score . - Then, calculate a softmax over all scores to get the weights
. - Generate the context vector
.
The context vector and previous decoder output are concatenated and given to the decoder to produce an output.