In a distributed system, we often need to send messages to multiple nodes (for membership, for example). Multicast organizes nodes into groups such that nodes can join and leave groups and multicast messages are sent to all members of a group.
There are two levels where we can implement multicast: network-level and application-level.
Network-Level Multicast (IP Multicast)
If the network supports broadcast (send message to every node), then we can simply build multicast on top of it by broadcasting the group message and having each receiver check if they’re in the group, delivering the message if so.
One example is IP multicast; there are a special range of IP addresses reserved for multicast, and nodes can use them to join, leave, and communicate with a group. Messages are sent via UDP (since TCP would require an established connection), and there’s no guarantee for reliability and ordering.
Application-Level Multicast (Gossiping)
If the network only supports unicast (send message between individual nodes), we can still use it “under the hood” to spread the message to members of the group. The most straightforward method would be the sender directly sending the message to everyone, but this can be inefficient—what if there are multiple recepients that are far from the sender but close to each other?
A better method is with an overlay: a structure connecting members of the group to optimize latency.
- Tree-based: we connect all nodes with a tree. This is maximally efficient but not robust to failure.
- Mesh-based: each node “knows” a few other nodes in the system, and we flood messages through the mesh (when a node receives a message it hasn’t seen, it sends to all neighbors). This is very robust, but it has many duplicates.
The mesh-based overlay is robust but wasteful. We can improve it with a gossip protocol:
- Each node keeps track of what messages it knows about.
- Once in a while, each node contacts one of its neighbors and asks about any new message the neighbor may have heard. If there are new message, the node downloads them.
This method is extremely robust to failures, but it’s not very fast, and there’s no good bound on latency.
Reliability
If we need reliability, we can implement it in a software layer that controls multicast delivery and sending. This layer will ensure that all members of the group will eventually receive the message. There are a few solutions:
- ACK: similar to TCP, receivers respond with acknowledgements when they receive the message. However, this will cause the sender to get flooded with ACKS and does not scale.
- NAK: instead of ACK, we can send negative acknowledgements. Nodes track sequence numbers to detect message loss, and if there’s a gap in the sequence, they unicast a NAK to the sender. This generally has less traffic than ACK, but flooding can still be a problem.
- Feedback suppression: NAKs are multicast to the entire group, and if a node notices a missing message, it waits a bit to see if anyone else has the same problem. It only sends the NAK if nobody else has.
- Hierarchical feedback control: group is structured into a hierarchy of subgroups, each with a “coordinator,” and if a node misses a message, it asks the coordinator. If the coordinator is missing it too, it asks the higher-level coordinator, and so on.
Ordering
Multicast messages may not be ordered if they’re delivered as they arrive. Applications such as videoconferencing or chatrooms will need to ensure ordering with additional mechanisms.
Just like with reliability, we’ll implementing ordering within a software layer. We can’t control when messages are delivered, but this layer will control when a message to given to the application. To store messages until they’re supposed to be given to the application, we put them in a hold-back queue.
There are three different types of ordering we can enforce:
- FIFO: in a node, for each sender, messages are delivered in the order they’re sent. No ordering is enforced for messages between different senders. This could be too weak if we need ordering between senders as well.
- Causal: if a multicast happens before another, then nodes will deliver the first before the second (see Causally-Ordered Multicast). This is stronger than FIFO, but it’s still possible for nodes to have messages in different orders.
- Total: if a node delivers a message before another message, then the other nodes must deliver the first before the second as well. This ensures that all nodes have the same exact order of messages.
FIFO Algorithm
To implement FIFO ordering, each sender keeps a counter
- Sender
sends message to node with counter . - Recipient
checks if : - If so, increment
and deliver the message. Also check the holdback queue to see if previous messages fulfill the condition above. - Otherwise, put the message in the holdback queue.
- If so, increment
Causal Algorithm
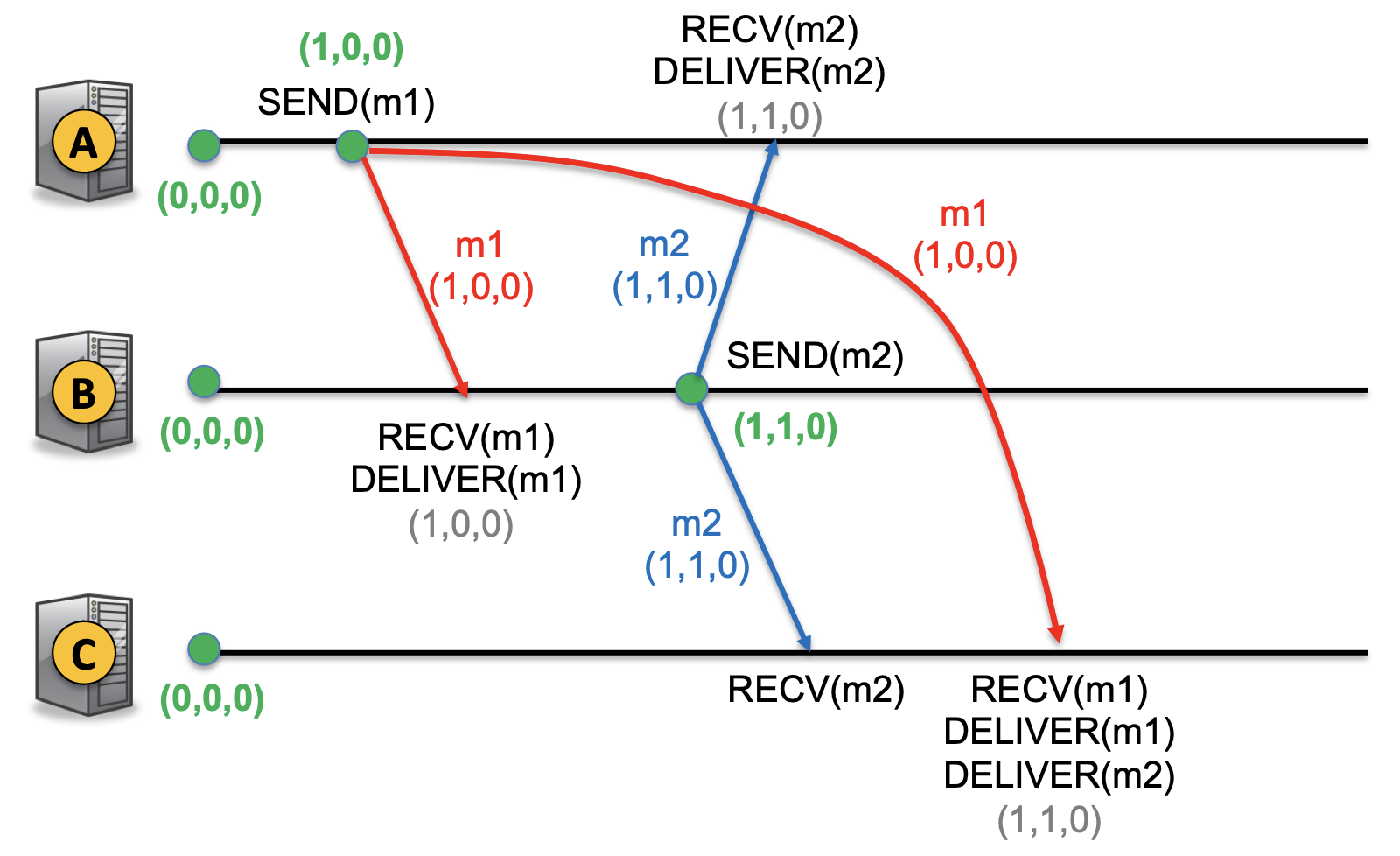
We can implement causal ordering with Vector Clocks. Messages should be delivered such that if someone reads message
To build this, nodes queue incoming messages; if
- It has seen all messages that
has gotten,
is the next message from ,
Total Algorithm
The simple solution for total ordering is to assign some node as a central sequencer and have it dictate the order all nodes should follow. However. this is a bottleneck and single point of failure.
Instead, we’ll have all nodes propose a sequence number for a new message, and the sender can collect proposals and use the highest proposed number as the true sequence number. Specifically, for each node, we track
- Sender requests proposals from nodes in group
. - Each recipient
responds with proposed number and puts in its holdback queue, marking it as “undeliverable.” - After sender receives proposal
from all group members, it picks and a tiebreaker ID and sends them to the members. - Each recipient updates the holdback queue’s
with and and marks it as “deliverable.” It also updates . - The holdback queue orders messages by the sequence number (with tiebreaker) and only delivers if it’s marked as “deliverable.”
Total ordering can be used to implement virtual synchrony, which makes a replicated distributed system behave like a non-replicated system with synchronous execution; if all replicas process requests in the same order, then they behave like a single node.