A system can fail in the middle of a long and expensive computation. Instead of starting from scratch, there are two complementary techniques we can use:
- Checkpointing: the system periodically saves its current state on disk, and nodes can go back to the checkpoint in case of crash.
- Logging: messages and nondeterministic events are logged, and after rolling back to a checkpoint, these logs are replayed to bring the node back to its last valid state.
Centralized Checkpointing
Let a “cut” of distributed execution be a prefix of each node’s local execution. The cut is “consistent” if for every event it contains, it also contains all events that happened before it—this means that every received message must have been sent.
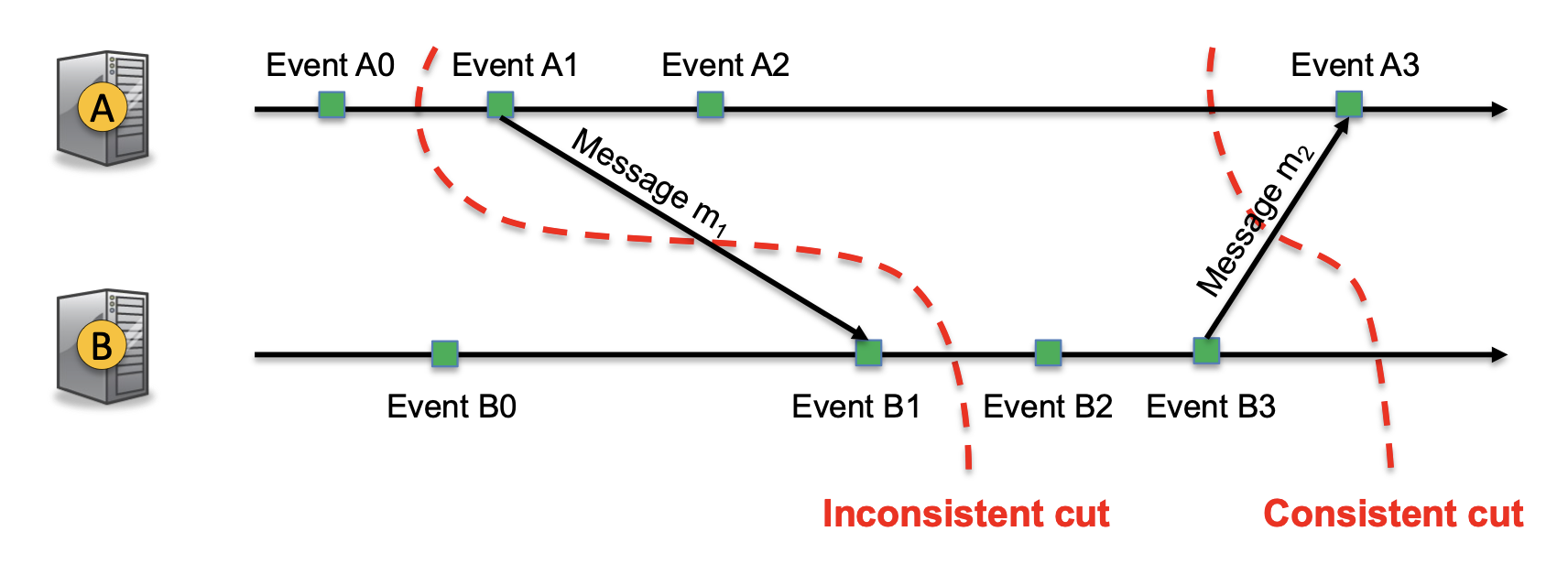
To roll back after a crash, we need to find checkpoints that form a consistent cut—called a recovery line. If the most recent checkpoints aren’t consistent, we need to go further back. However, if nodes take checkpoints independently, it is very unlikely that any cut will be consistent; in other words, we need the nodes to coordinate their checkpointing.
Centralized checkpointing provides a solution similar to Two-Phase Commit (2PC):
- Coordinator sends “checkpoint” to all processes.
- When a process receives the message, it takes a checkpoint, queues ongoing messages (to avoid inconsistency), and responds with “ack.”
- Once all “acks” are received, the coordinates sends “done,” allowing queued messages to be sent.
While this solution works, it’s not ideal since it needs a central coordinator and queued messages; it also loses in-flight messages, ones that were sent before the sender’s checkpoint but received after the recipient’s checkpoint.
Chandy-Lamport
What we really want is a “snapshot” of the system containing both checkpoints and in-flight messages. We can do so with the Chandy-Lamport algorithm, which is also fully distributed and does not need to queue messages:
- Let every node
have direct, reliable FIFO channels to other nodes . - When
wants to initiate a snapshot: - It takes a local checkpoint.
- It sends a special marker message to each outgoing channel.
- It begins recording messages that arrive on incoming channels.
- When node
receives the marker from on channel : - If it hasn’t taken a checkpoint, it takes the checkpoint, sends a marker to each outgoing channel, records the state of
as empty set, and begins recording messages on all other incoming channels . - If it already took a checkpoint, it stops recording messages for
.
- If it hasn’t taken a checkpoint, it takes the checkpoint, sends a marker to each outgoing channel, records the state of
- Once
receives a marker from every other node, the algorithm terminates.
With this, the recorded messages are the missing in-flight ones at snapshot time.