A single core can only be so fast, so a natural extension is to have multiple cores per machine. Note that this requires software to explicitly expose parallelism.
Shared Memory Model
A multiprocessor runs multiple 🧶 Threads in parallel that access a single shared memory. The simplest implementation of this is having multiple pipelines that shared the same instruction and data caches, like below.
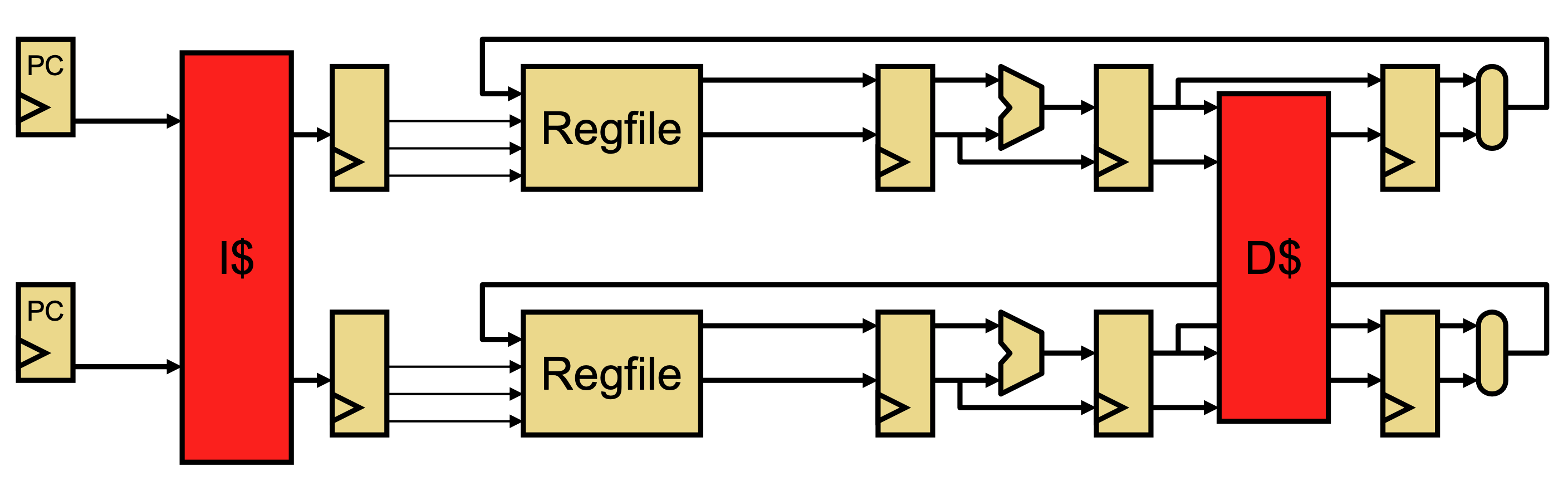
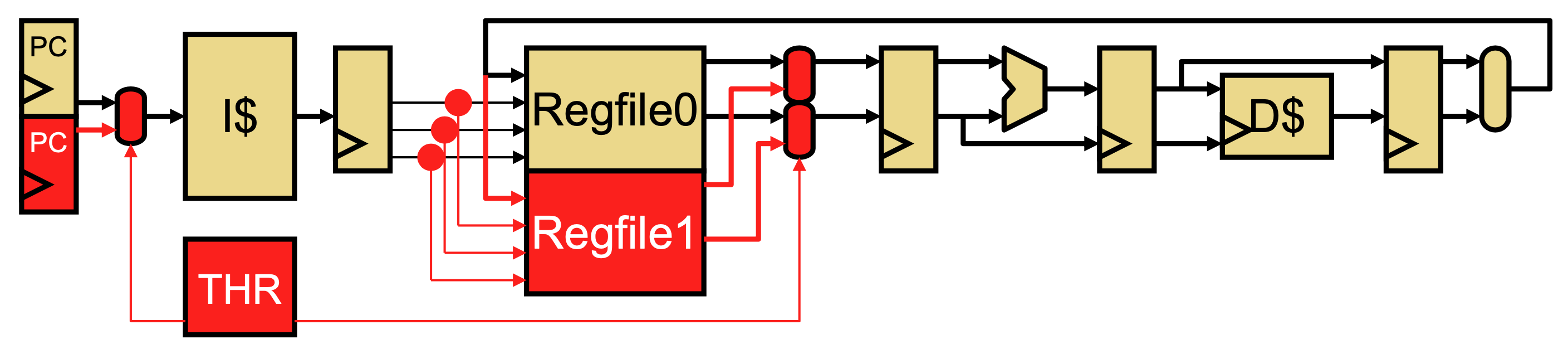
Another implementation is hardware multithreading (each hardware thread can run one software thread), where we duplicate the PC and register file, but share the rest of the pipeline. This allows us to interleave more independent instructions, increasing utilization and throughput.
Cache Coherence
Sharing L1 caches is slow, so we can add private per-processor caches. However, we need to coordinate them with cache coherence and enforce shared memory.
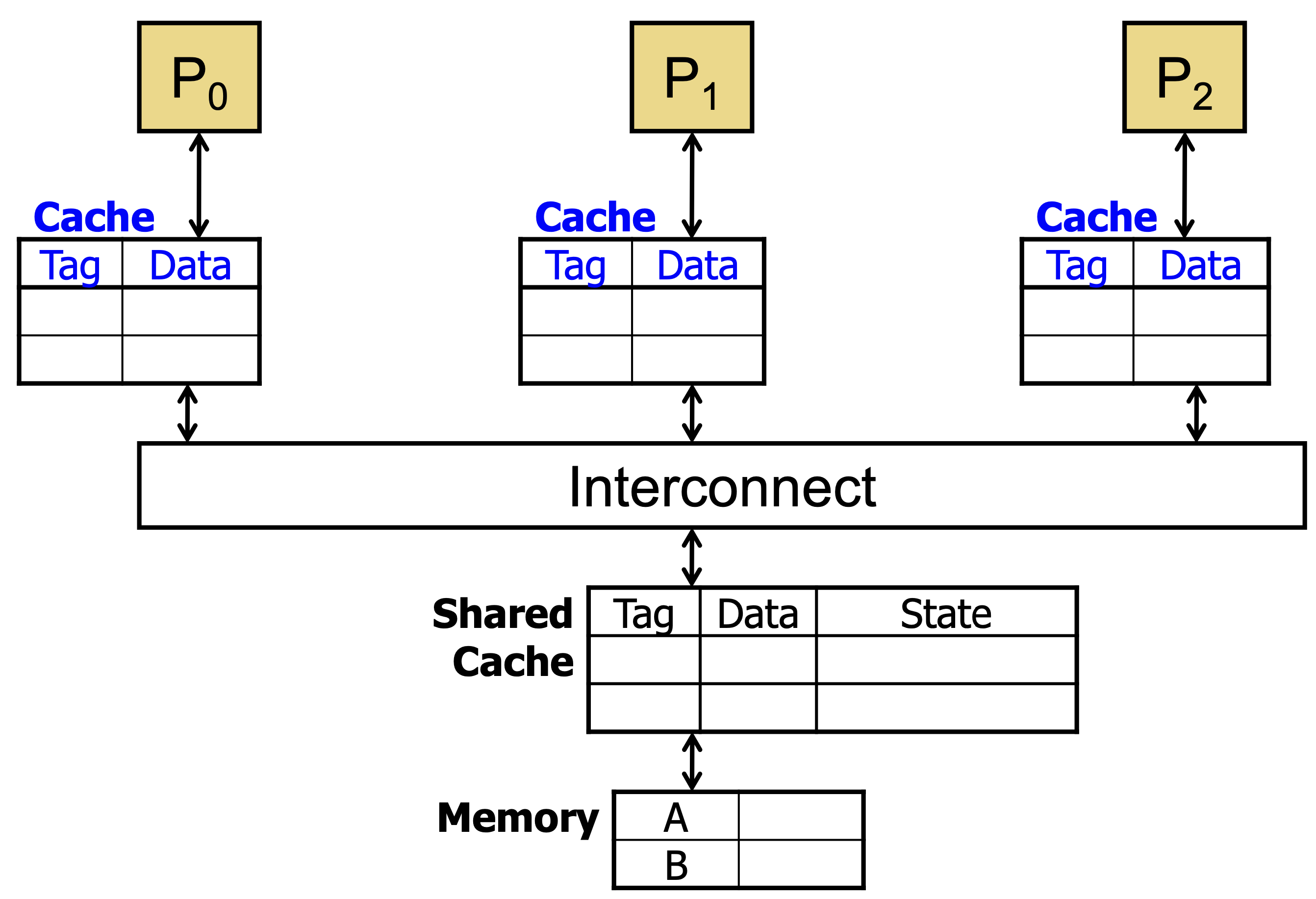
The problem arises when one processor issues a store: with [[💵 Hardware Cache#Write Propagation#Write-Back Caching]], the dirty value will only be in its private cache, and other processors that cess that address will see the old value.
The simple solution is to write-through updates to all caches (called update-based coherence), but this is expensive. It’s much more common to use invalidation-based coherence, with some example protocols below.
VI Protocol
One solution, called Valid-Invalid (VI), is to have the shared cache keep track of which private cache has a piece of data. When another processor asks for it:
- The second processor gets the data from the tracked private cache.
- The second processor puts the data into its own private cache (validate).
- The first processor removes the data from its own private cache (invalidate).
However, this means we can only have one copy of data, even if it’s read-only.
MSI Protocol
The Modified-Shared-Invalid (MSI) protocol addresses this by allowing multiple read-only copies and a single read-write copy. Each private cache tracks its state (M, S, or I), and the shared cache keeps a list of sharers.
If a processor wants to write to something in the shared state, it has an upgrade miss and must:
- Find other copies via shared cache, then invalidate them.
- Change its own state to modified.
- Update shared cache to only have that processor.
MESI Protocol
If we want to load and then store to the same location, MSI will incur a load miss and an upgrade miss—even if the block isn’t actually shared. Since lots of programs have private data, we can add an exclusive state to MSI that indicates “I have the only cached copy, and it’s clean.”
When a processor tries to load something that isn’t shared by other processors, its state becomes exclusive. Then, when it tries to store, it can directly switch to modified state without an upgrade miss.
MOESI Protocol
Finally, we note that there’s some redundancy between the dirty bit and coherence state: exclusive is always clean, and modified is always dirty, but shared can be clean or dirty (if block is modified, then shared with another processor). We can discard the dirty bit and split shared into read-only shared (clean) and read-only owned (dirty).
Now, we know that owned blocks must be written back, and shared states don’t. Note that we only need one copy to be owned, and the rest can be shared.