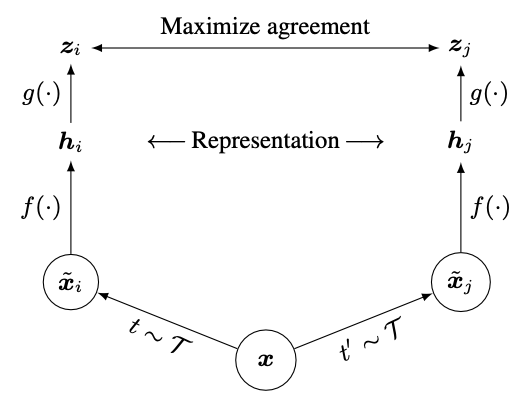
SimCLR is a contrastive learning framework that learns a latent representation by maximizing similarity between different augmentations of the same sample. The framework has four components:
- Data augmentation composition techniques that produce two views of a data sample,
and . - A base encoder
that extracts the representation . - A projection head
that maps representations to contrastive space, . Though it’s possible to optimize directly on the representations, the contrastive loss may discard some valuable representation information (like color or orientation transformations) that aren’t crucial for measuring similarity. - The contrastive loss that finds the corresponding
for some among a set with negative samples .
Specifically, we’ll first define similarity as cosine similarity,
Then, we’ll perform the following for multiple iterations:
- Sample a minibatch of
examples, then augment them to form views. For each , we’ll treat the other views as negative samples. - Optimize a temperature-scaled ℹ️ InfoNCE loss,