Normalizing flows transform a simple latent distribution into the distribution of a dataset and vice versa. This allows us to sample new images from the dataset distribution and solve other inference problems.
If we could invert
Note
For invertibility, the dimensions and
and must be equivalent.
To transform a random variable’s distribution, we need the change of variables formula
where
where
A big advantage of this method is that we can now stack transformations on top of each other, as long as they’re all invertible. Hence, we can capture complex distributions be iteratively transforming a simple one.
Variants
Planar Flow
Planar flow uses the transformation
where
Note that we need to restrict the parameters for the mapping to be invertible, so
NICE
Nonlinear independence components estimation (NICE) introduces additive coupling layers and rescaling layers. The former are composed together, and the latter is applied at the end.
- Additive coupling partitions
into disjoint subsets and . Then, the corresponding subsets of , and , are equal to the following:
where
Note that by design, the Jacobian of the forward mapping for additive coupling is a lower triangular matrix
and the product along the diagonal is
Real-NVP
Real-NVP builds on the additive coupling layer from NICE by adding extra complexity via scaling,
where
Masked Autoregressive Flow
Masked autoregressive flow (MAF) connects the flow idea to 🕰️ Autoregressive Models that are defined by
If we let the transitions be parameterized Gaussians, we have invertible functions
The Jacobian is lower triangular and can be computed efficiently. However, generation is sequential, taking
Inverse Autoregressive Flow
Inverse autoregressive flow (IAF) addresses the slow generation problem by inverting the neural networks, so we have
where
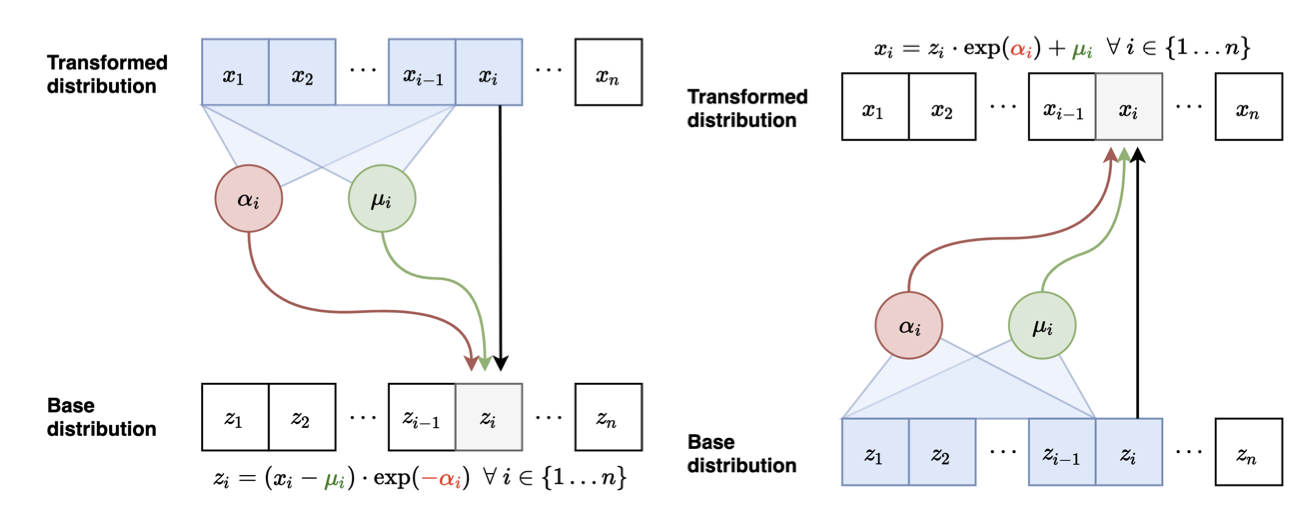
However, the inverse mapping from
Parallel Wavenet
Parallel wavenet combines the best from MAP and IAF speeds by training a teacher and student model. The teacher uses MAF and the student uses IAF. The teacher can be quickly trained via MLE, and the student aims to mimic the teacher by minimizing
Since