Principle Component Analysis (PCA) is used for dimensionality reduction, decomposing datapoint vectors
Note that we first mean center the data, subtracting
Projection
For an individual vector
To reconstruct
We can also write this in matrix form; for data
where
Optimization
We can derive the analytical solution to PCA by following either methodology: minimizing distortion or maximizing variance.
Minimizing Distortion
Distortion is defined as
Plugging in our definition for
This shows that distortion is the sum of squared scores that we leave out. Plugging in the equation for the scores as defined above, we find that distortion actually equals
where
To minimize distortion, we first observe that the covariance matrix is symmetric and therefore diagonal in its eigenvector basis. Because it’s diagonal, the axes are independent, and we minimize distortion by leaving out the dimensions that have minimum variance.
Note
For a more mathematical proof, we use Lagrange multipliers. For
, to minimize with the constraint that , we differentiate the Lagrangian to get , the definition of an eigenvector.
Setting
Observe that by setting the basis in this way, our basis is orthogonal. In other words, the components are uncorrelated, and the transformation of
Maximizing Variance
Variance is defined as
Note that since we subtract off the mean from
Observe that the middle summation is again a form of
Therefore, by maximizing variance, we’re also minimizing distortion (and vice versa). If we add them together, we get their inverse relationship
Visualization
As for a visual example, in the image below, we can see that the eigenvectors and their associated eigenvalues (the eigenvector’s magnitude) fit the distortion-minimization variance-maximization objective.
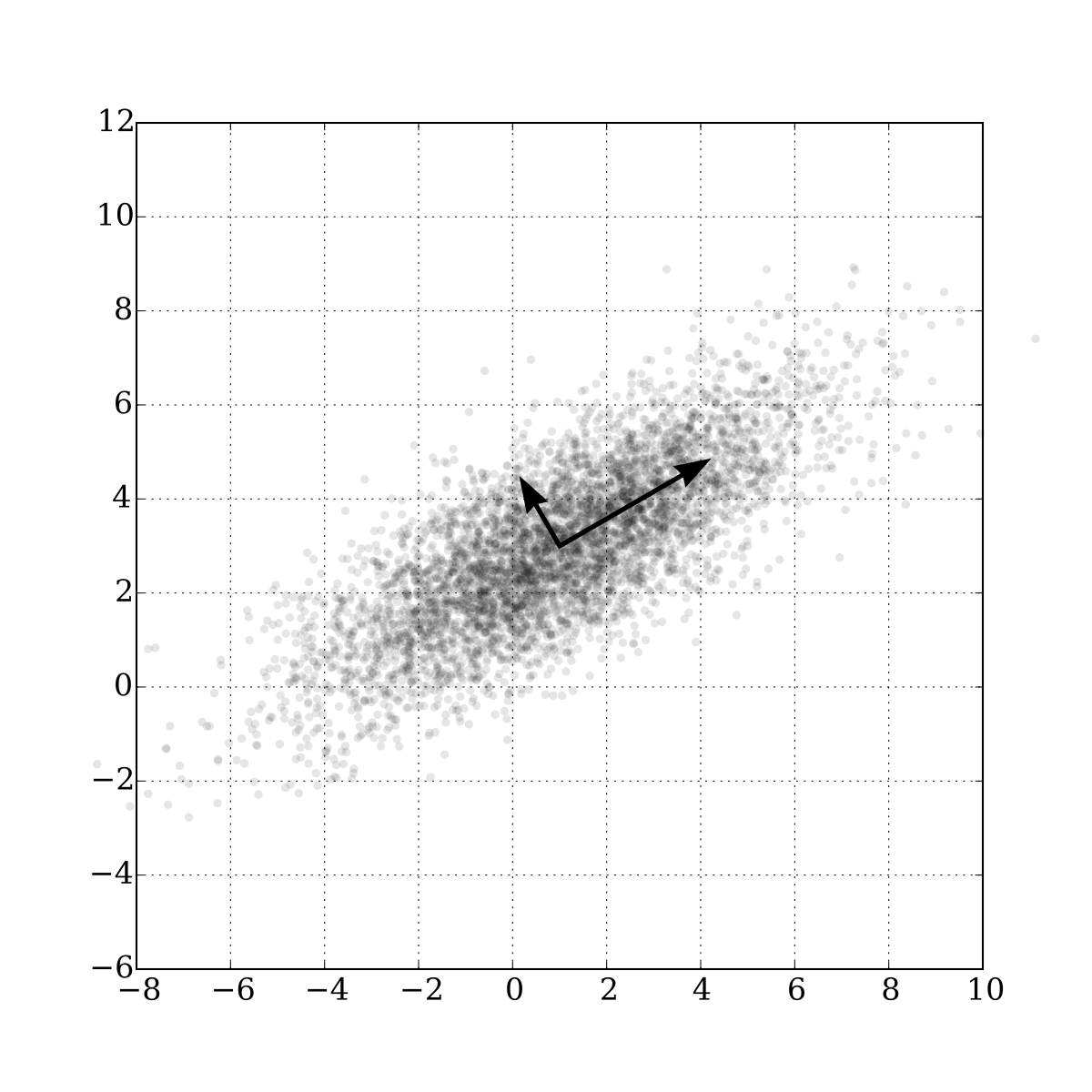
Projecting points onto the largest eigenvector (going from 2D to 1D) will maximize the spread since this axis has largest variance. It also minimizes the distortion, geometrically interpreted as the distance from each point to our new axis.
Computation
There are two methods to compute the PCA’s eigenvectors. The direct way requires us to find the covariance matrix, which may be computationally expensive; an alternative method uses SVD to avoid this cost.
Direct PCA
Given data
Find the
PCA via SVD
Given data
Compute 📎 Singular Value Decomposition
Note that the singular values calculated by SVD for
Variants
PCA has a few variants that add onto its basic functionality.
- Sparse PCA adds an
penalty to the size of the scores and components in our distortion equation, so the optimal values are no longer eigenvectors and require alternating gradient descent. - Kernelized PCA can model a nonlinear transformation of the original data.