MapReduce is a framework for performing structured computations on large amounts of data—so much data that compute and storage must be split across multiple machines. Thus, we need to solve problems with coordination, load balancing, etc.
For simplicity, lets abstract the data as key-value pairs
- Map: takes
and produces some intermediate pair(s), essentially organizing them into “stacks.” - Reduce: takes groups of
pairs with the same key and produces some pairs for the output, essentially “aggregating” the information for the same key ‘.
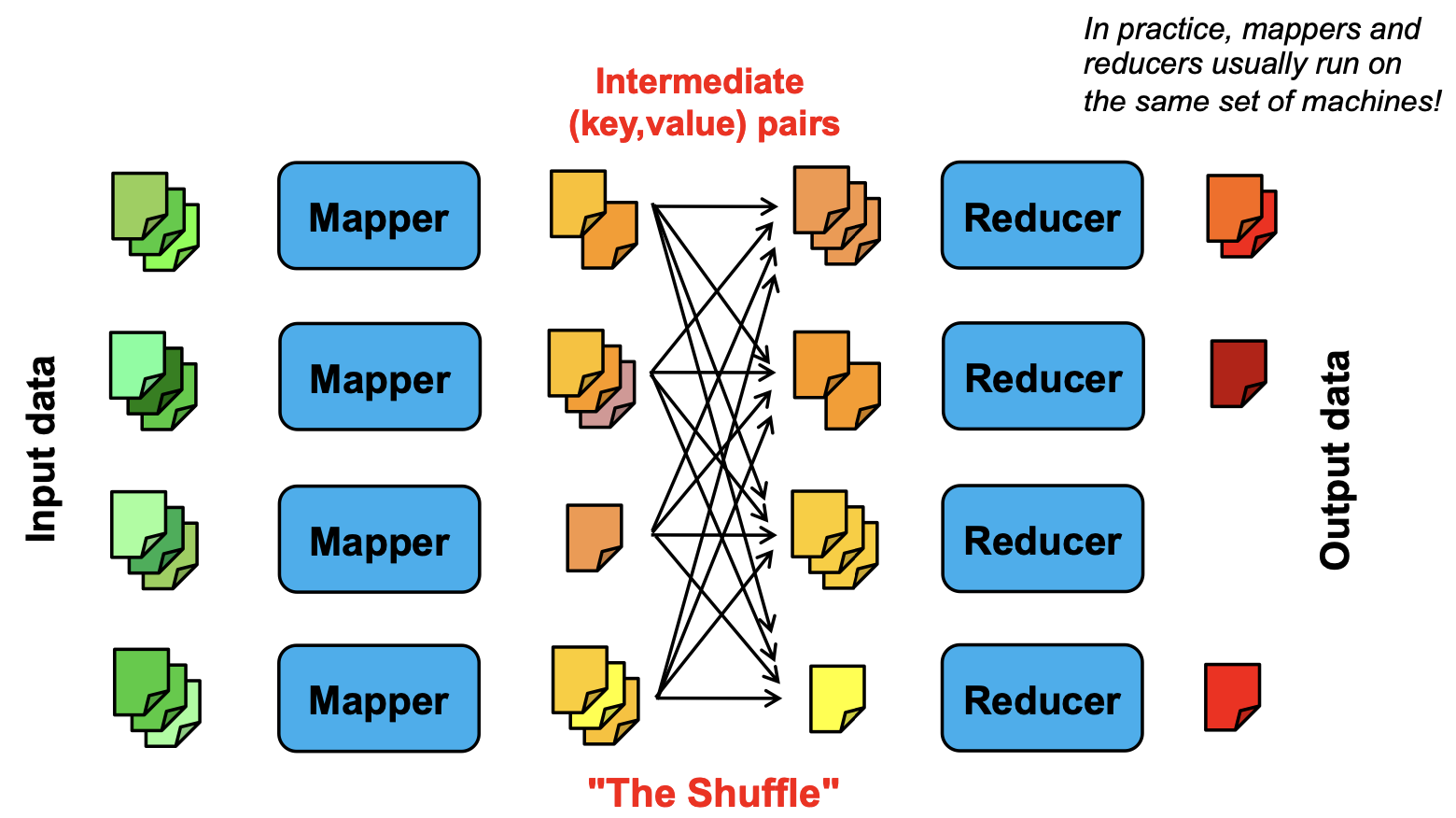
For example, to find the number of occurrences of each word in a set of documents, the map function reads each documents and maps each word to
To design a system, we must consider the limitations and responsibility of each function:
- Map: only looks at individual key-value pairs, cannot use other key-value pairs. However, it can emit more than one intermediate key-value pair.
- Reduce: aggregates multiple values from the same intermediate key.
Implementation
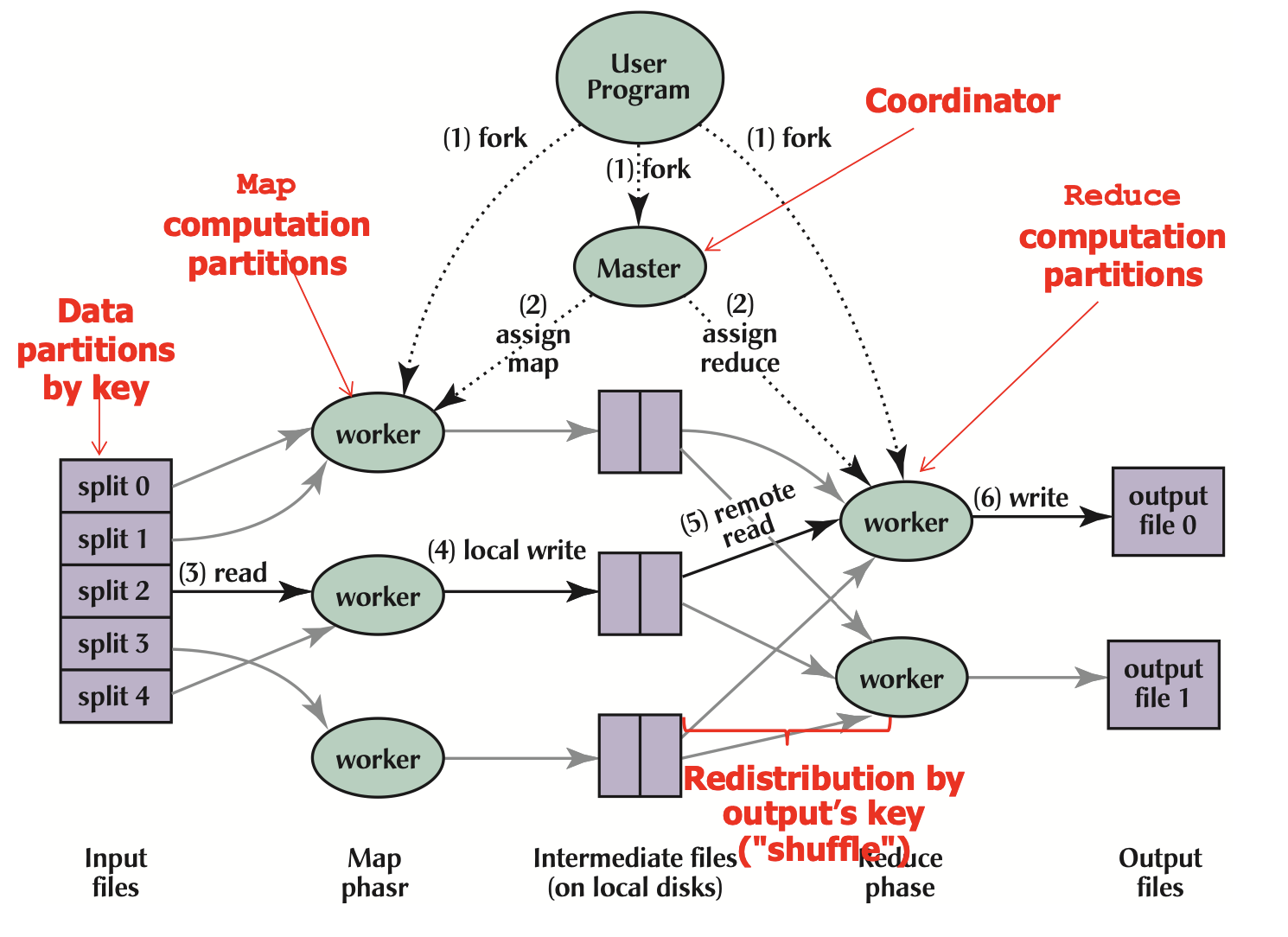
To implement this system, we need:
- 📦 Distributed Storage System to store inputs, outputs, and intermediate results. For example, 🔎 Google File System (GFS).
- A driver program (master), which specifies the input and output locations, the mapper and reducer functions, and more. Notably, it should assign tasks to maximize locality, making nodes do work on data replicas it’s already storing.
- The runtime system, which controls nodes and supervises execution.