Feature-wise linear modulation (FiLM) is a general technique for influencing a neural network’s output via some external conditioning input. A FiLM layer allows us to inject conditioning into the intermediate activations by using conditioning to perform an affine transformation on the features.
Formally, FiLM learns a “generator” consisting of two functions
Then, for a network’s activations
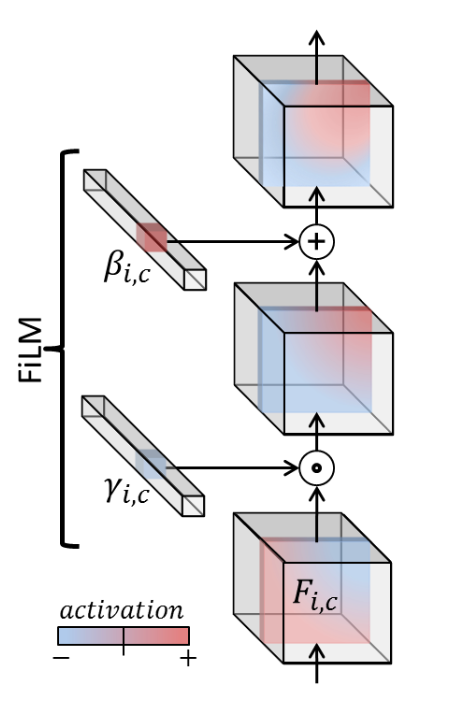
Notably, empirical results show that FiLM doesn’t require
VQA Model
FiLM is especially effective with vision-language tasks due to the multimodal input capability. Specifically, for visual question-answer problems, we have a 👁️ Convolutional Neural Network visual pipeline with FiLM layers and a ⛩️ Gated Recurrent Unit generator. The GRU is responsible for processing the question semantics, and injecting this information into the CNN allows us to perform accurate answer predictions.