Theory
Recurrent neural networks handle sequential data, modifying the 🕸️ Multilayer Perceptron structure to maintain information about previous parts of the sequence when processing at each time-step. The following is an illustration of the general structure, where each horizontal “layer” processes one unit of the sequence.
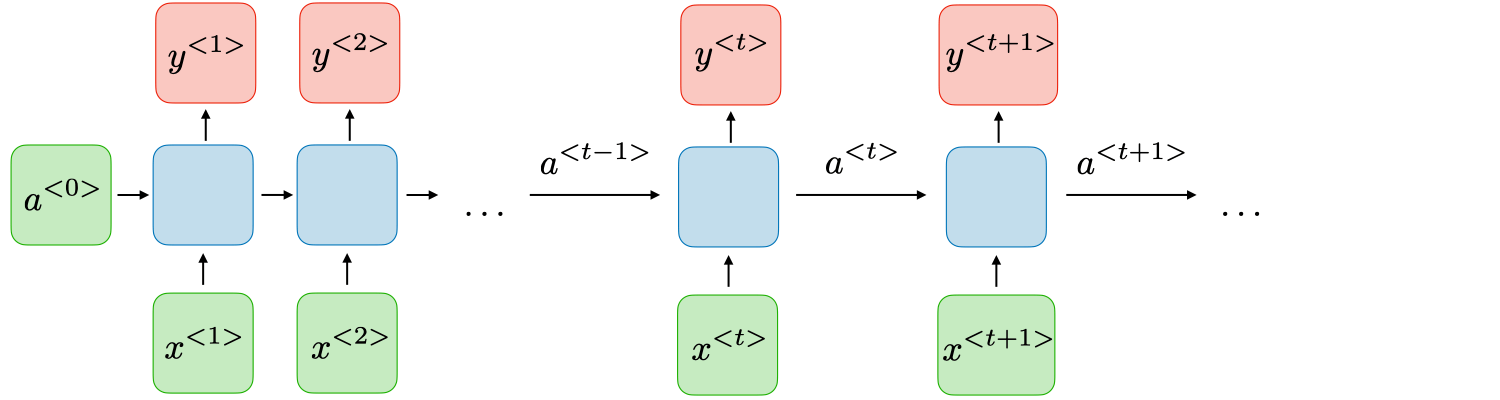
Whereas a standard neural network simply takes the input and produces an output, the RNN, pictured as the blue box, also receives the previous time-step’s hidden activation
Model
The model itself shares many similarities with other neural networks. The main addition is an extra set of weights that are applied to the previous activations.
Training
Training is done via backpropagation at each point in time.
One major problem RNN faces is exploding and vanishing gradients. When we backpropagate through time, if the change in consecutive time steps is not exactly one, the gradient decreases or increases exponentially, thus causing changes to earlier time steps to be in the extreme. 🎥 Long Short-Term Memory and ⛩️ Gated Recurrent Units are more advanced RNNs designed to solve this problem.
Prediction
To predict, the input sequence is split into individual units, which are sent in order to the RNN. The RNN can produce any number of outputs for one-to-one, one-to-many, many-to-one, and many-to-many tasks.