GANs are generative models that learn via an adversarial process, which implicitly models the data density function. It consists of a generative and a discriminative network; the former generates samples from a random latent space, and the latter ties to distinguish between generative outputs and samples from the training data.
Specifically, we input random noise
For an optimal discriminator
where Jenson-Shannon Divergence
Minimizing this objective is this analogous to making the generator’s distribution close to the data distribution.
For training, we alternate between gradient ascent on slightly-modified parts from the minimax objective:
Challenges
The above theory, when applied empirically, is often unstable with a few main problems.
- Unstable optimization and oscillating loss likely caused by imbalance between discriminator and generator effectiveness or oscillation between modes.
- Generator mode collapse, causing it to generate duplicates consisting of modes of the distribution.
f-GAN
Instead of using the Jenson-Shannon Divergence, we can generalize the GAN objective to any 🪭 F-Divergence,
for some
To do this, we use the Fenchel conjugate, defined as
Intuitively,
Plugging this into our
We thus have a lower bound on our objective and can choose any
which is a generalization of the original GAN objective.
Wasserstein GAN
The Wasserstein GAN notes that our divergence requires the support of
To avoid this limitation, we can instead use the Wasserstein distance
where
To convert this into two expectations, we use the Kantorovich-Rubinstein duality,
where
Progressive Growing
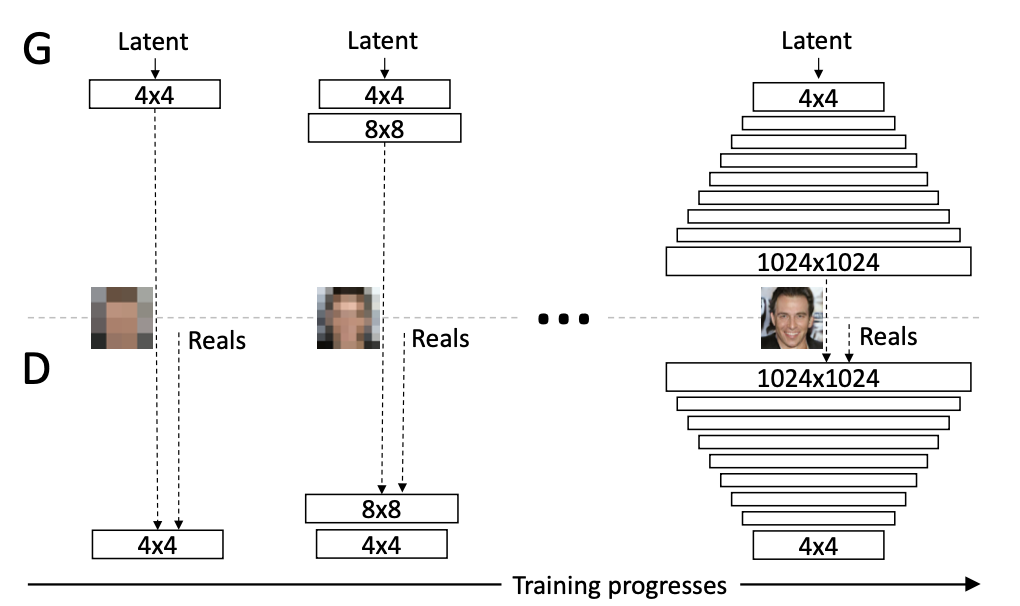
Training instability often arises from the generator and discriminator improving at different levels. To address this problem, we can start by generating small 4x4 resolution images, then slowly scale up the resolution by adding more layers onto the generator and discriminator. This not only encourages faster convergence but also allows the models to see many more images during training due to smaller hardware requirements in the early stages.
BiGAN
BiGAN infers the latent representation of a sample
Our discriminator objective is to differentiate