Noise conditional score networks (NCSNs) seek to approximate the true data distribution
of the distribution. 🎼 Score Matching is a natural way to train
However, because our data distribution is concentrated around manifolds in the full data space (as per the 🪐 Manifold Hypothesis), our model doesn’t learn accurate scores for the rest of the image space, preventing convergence and mixing between modes. A visualization is below.
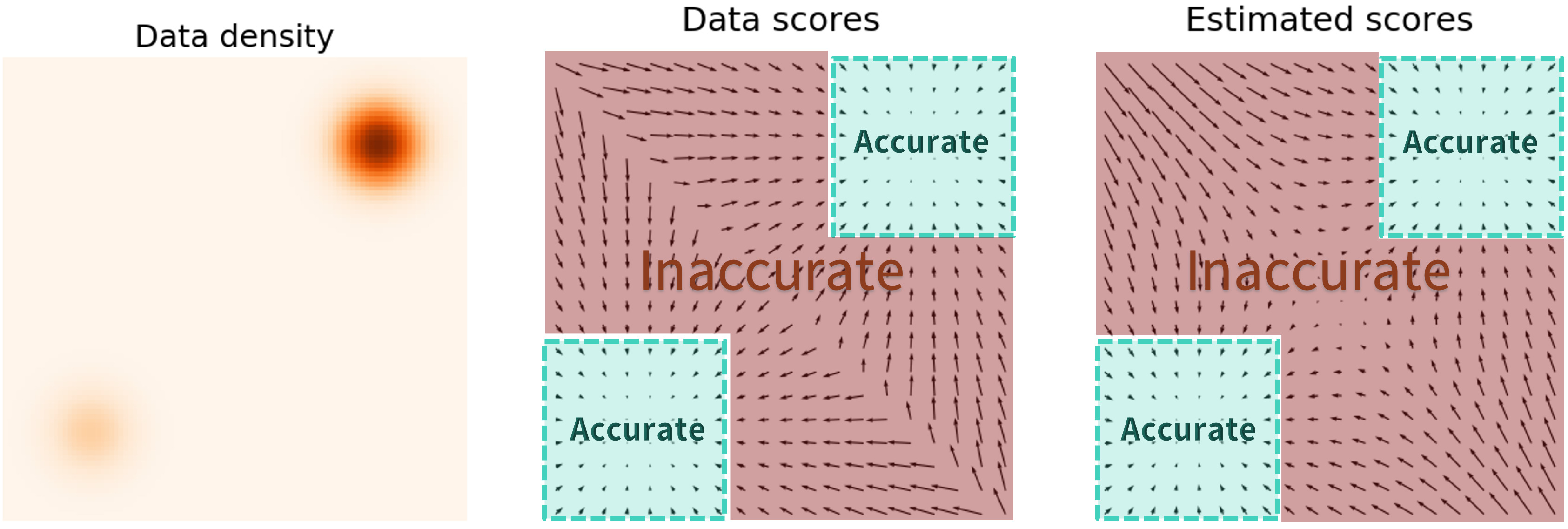
The solution is to perturb the data distribution with multiple levels of noise, which populates the low-density regions and allows our model to learn scores from them. Specifically, we set noise scales
as our noisy distribution for each scale. Our score model is now conditioned on the scale as well, so we have
We can still train using a weighted sum of Fisher divergences
where
To sample, we use annealed Langevin dynamics, which essentially performs Langevin dynamics for