🦾 Transformers work extremely well for sequence processing, and its advantages can also be applied to image data. For classification, we use a slightly-modified transformer encoder and feed it a sequence of image patches that partition the image.
We first split the image into multiple patches, then treat each patch as a token in the sequence; note that we also need to first convert these patches into embeddings before feeding it into the encoder. Positional encodings are also learned during training.
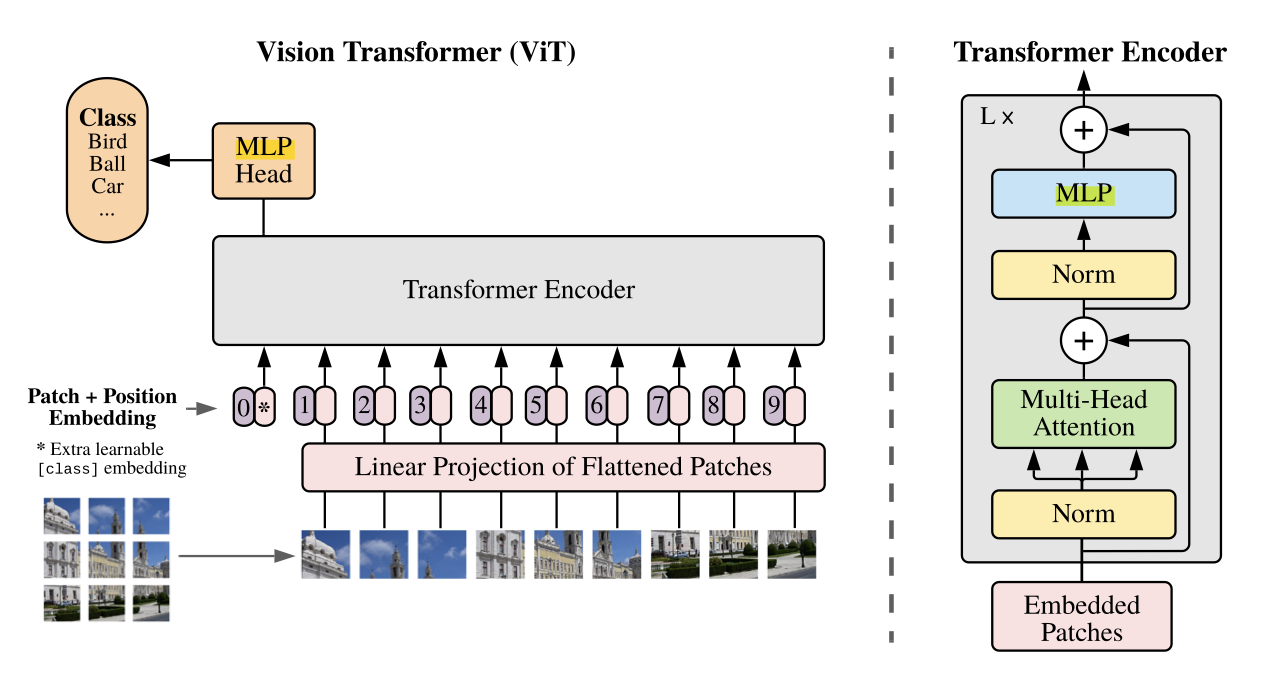
Instead of the standard feed-forward block, we use multilayer perceptrons. Finally, note that we completely remove the decoder as the encoder is responsible for capturing information from the patches, and the MLP head at the end finds the correct class.
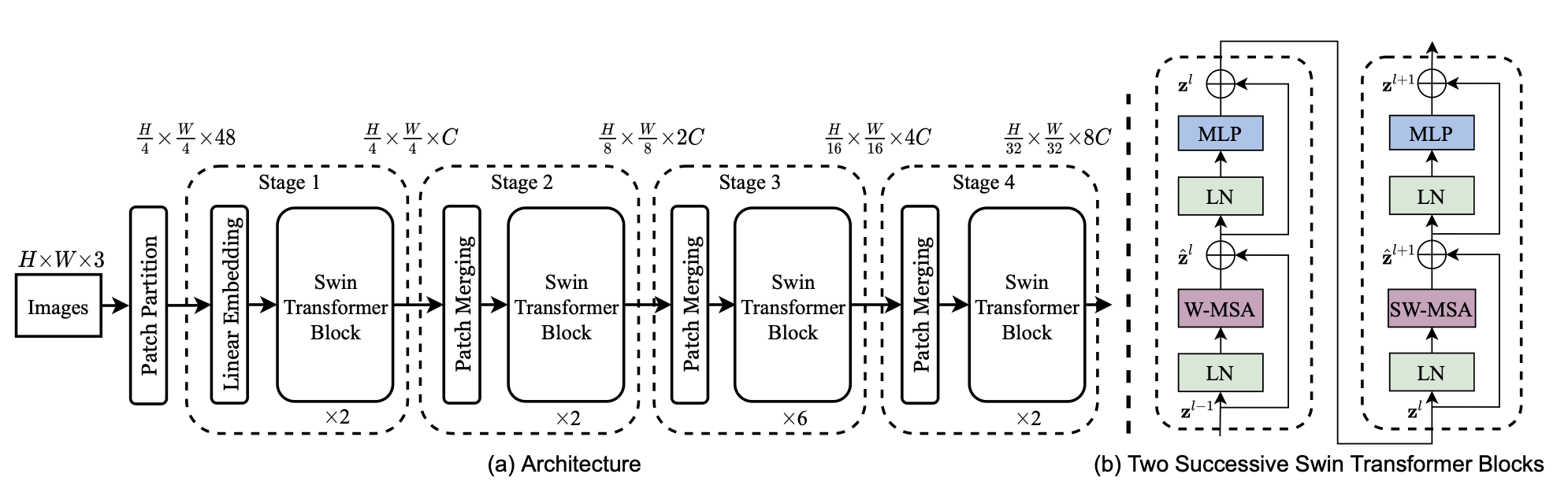
Swin Transformer
Swin transformers extend the setup above to incorporate vision-specific properties. Specifically, it introduces two ideas to speed up computation and incorporate scale:
- Self-attention is only applied across tokens within “windows” of neighboring tokens (as illustrated below) rather than all tokens in the image. These windows are alternated between the two patterns below to ensure signals can be propagated across boundaries.

- After a transformer block,
patches are merged into one patch (similar to pooling in a 👁️ Convolutional Neural Network). This constructs a hierarchical representation of the image.
The following is an example architecture: