The convolution of two functions
Intuitively, this is a fancy multiplication operation on two functions that flips the domain of
In computer vision, convolutions are generally applied in 2D over 🏞️ Images. If we let
By flipping the kernel, convolutions are associative, commutative, and distributive. They also preserve linear independence,
Impulse Function
The impulse function is a 2D array where one index is
- For an impulse function
with in the middle, . - For impulse functions
with in a certain direction, shifts towards that direction.
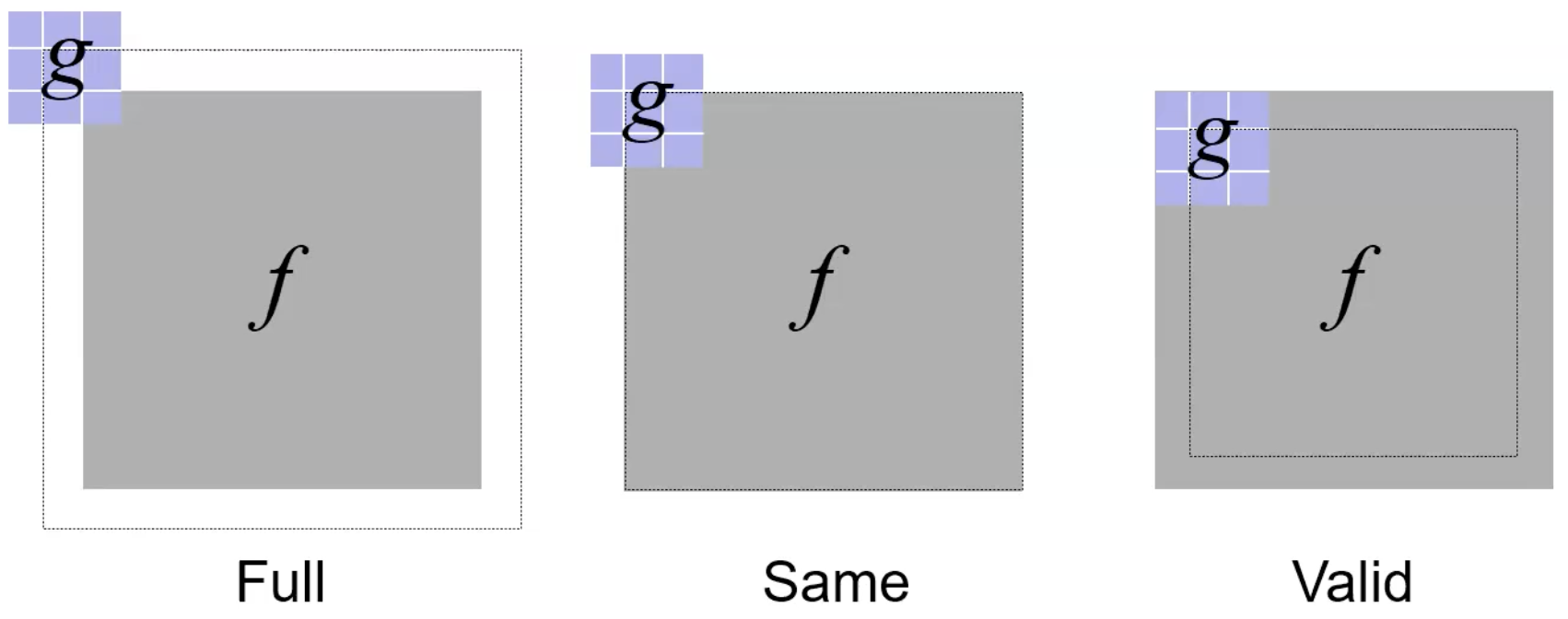
Padding
If we apply an
There are three common padding methods: full maximizes the dimensions, same preserves the same dimensions, and valid shrinks dimensions (and uses no padding).
Filtering
A very similar idea is filtering, which performs the same operation as a convolution without flipping
Note that in 👁️ Convolutional Neural Networks and most machine learning systems, we actually use learned filters instead of convolutions. The reason is that since the values are learned anyways, there’s no difference between flipping