DINO is a self-supervised pre-training framework that extends pre-training ideas from natural language processing (like in 🧸 BERT) to vision. It performs knowledge distillation with no labels, using a student-teacher setup where the teacher is based off the student.
Formally, we have a student with parameters
In order for the two networks to learn meaningful semantics, we give them different data: for an image
In other words, we want the student to output the same probabilities as the teacher, even with a local view of the original image.
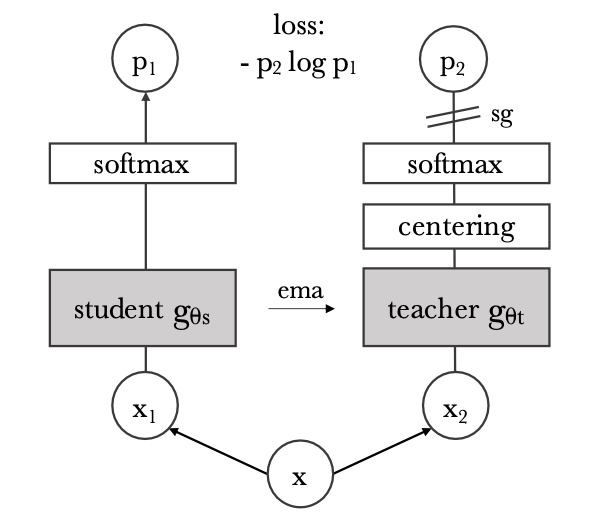
Both networks use the same architecture
Note that this formulation is similar to 🐼 MoCo’s momentum encoder, but this setup doesn’t use a queue or contrastive objective. Also, to avoid collapse, we perform centering and sharpening the teacher’s outputs; that is, we maintain a center
that’s applied to the output prediction and also set up a low temperature
Using a 🦿 Vision Transformer as the backbone for
