K-Nearest Neighbors assumes that similar will have similar ; in other words, the label of any unknown can be estimated by checking the labels of similar that we do know.
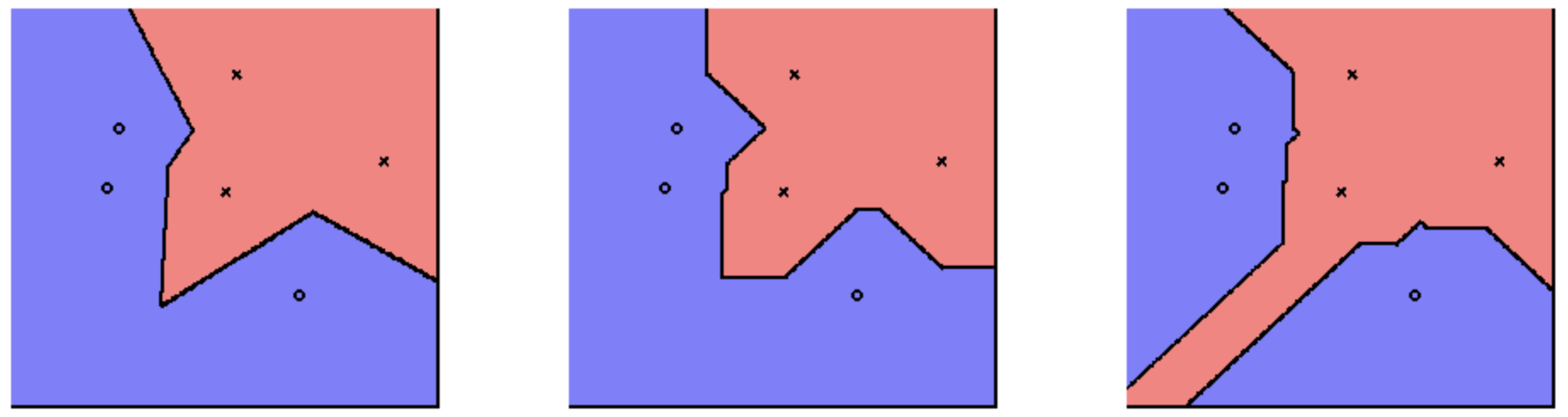
Specifically, we’ll check the most similar data points, calculated by some distance function , and get an aggregate of their labels . The distance is commonly a 📌 Norm, usually or .
The following visually demonstrates the effect of different norms for the distance function, using , , and respectively (with ).
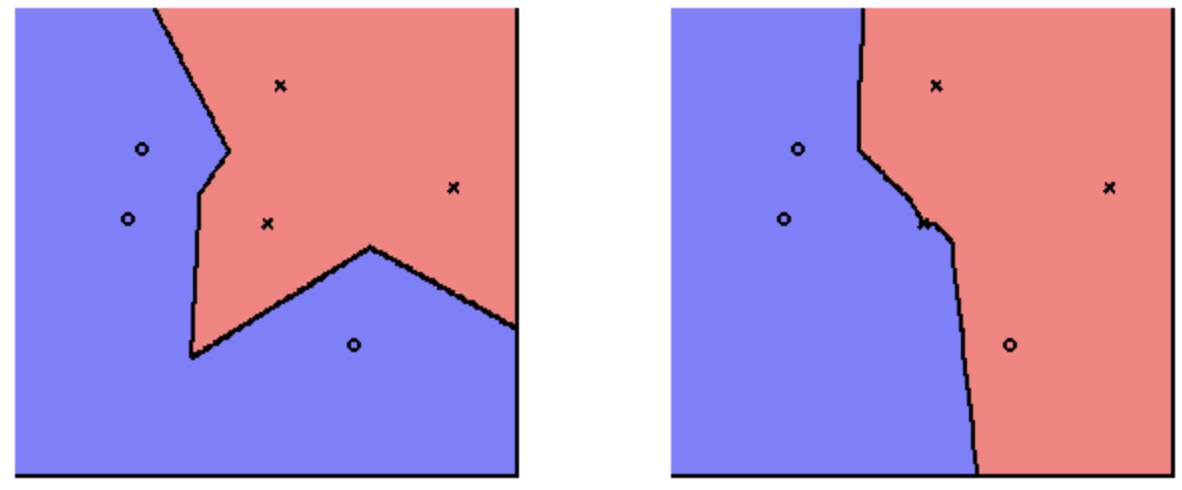
also affects our decision boundary, with higher giving a smoother separation. Below is a comparison between and .