Theory
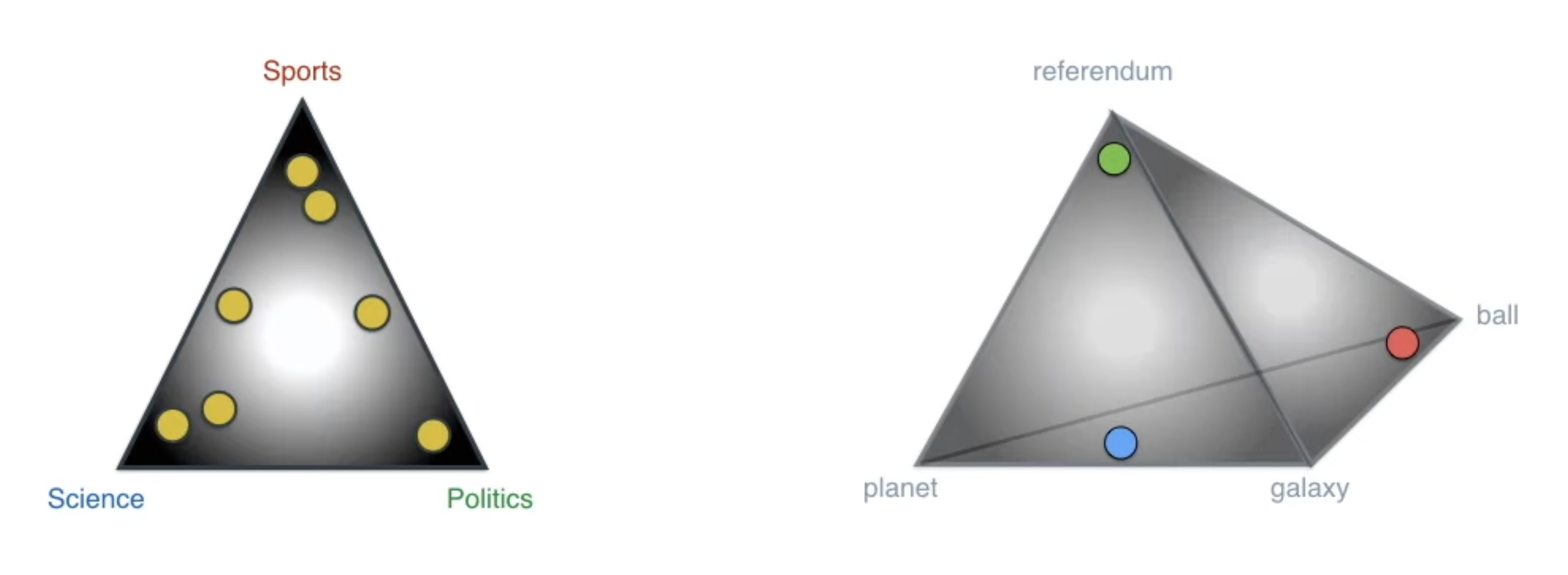
Latent Dirichlet Allocation is an unsupervised method for document classification that comes up with the topic classes on its own.
We treat each document as a mixture of topics, and each topic has a different probability distribution of words. The topic distribution for a document and word distribution for a topic come from two Dirichlet distributions
Info
Each topic is similar to a 👶 Naive Bayes model, producing words with different probabilities.
Fundamentally, LDA follows a generative process. To create a document,
- Choose a topic distribution
for our document. - For each topic
, choose a word distribution . - For each of the
word spots, choose topic . - Then, for each spot and its chosen topic
, choose a word from the topic’s distribution, .
It can be optimized with 🎉 Expectation Maximization, alternating between calculating probabilities for
Model
Consists of parameters
During training, we maintain hidden variables
Training
Given training data
Then, alternate until convergence, starting with the M step, then E step.
- Given topic assignments, for each topic, estimate
- Using
from earlier, for every token estimate
We can use this probability to pick new topics for each word, giving us
Prediction
To predict the topic for a given document, find the topic that maximizes the product of probabilities of words in the document belonging to that topic.