Assume our input data is linear. That is, it follows the following function.
Noise can be interpreted as randomness or effects of other features not included in . Another way to write is as follows.
Linear regression fits a linear model that maximizes the fit, which equates to minimizing the error or maximizing the likelihood , both of which are defined below.
To maximize the likelihood, we find that maximizes the log-likelihood, which simplifies the math. This gives us an equation that’s analogous to minimizing .
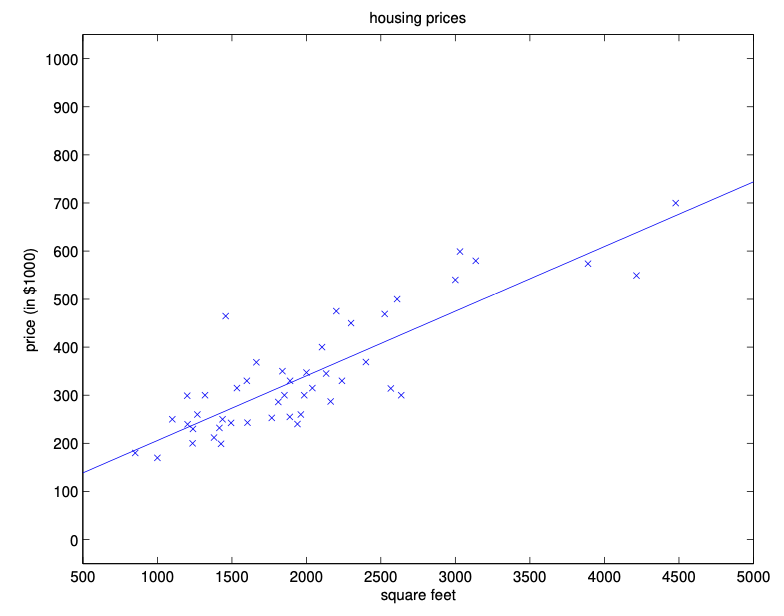
The following is an example of performing (MLE) linear regression on single-feature .
Note that with regularization (MAP), we need to incorporate an extra term to our error
that pushes the weights toward . This makes MAP not scale-invariant as the scale of the weights now matter; MLE, on the other hand, is scale invariant and will always find the parameters that maximize likelihood.
Given training data and , assume weight prior . Let regularization term , then closed form solution is as follows.
If we don’t use a prior, our MLE closed form is as follows
To get bias term , add a new feature for all training examples; the coefficient for this feature is our bias
Note that computing the closed form solution may be expensive, in which case 🗼 Least Mean Squares provides an alternative optimization method using gradient descent.
 Note that with regularization (MAP), we need to incorporate an extra term to our error
Note that with regularization (MAP), we need to incorporate an extra term to our error