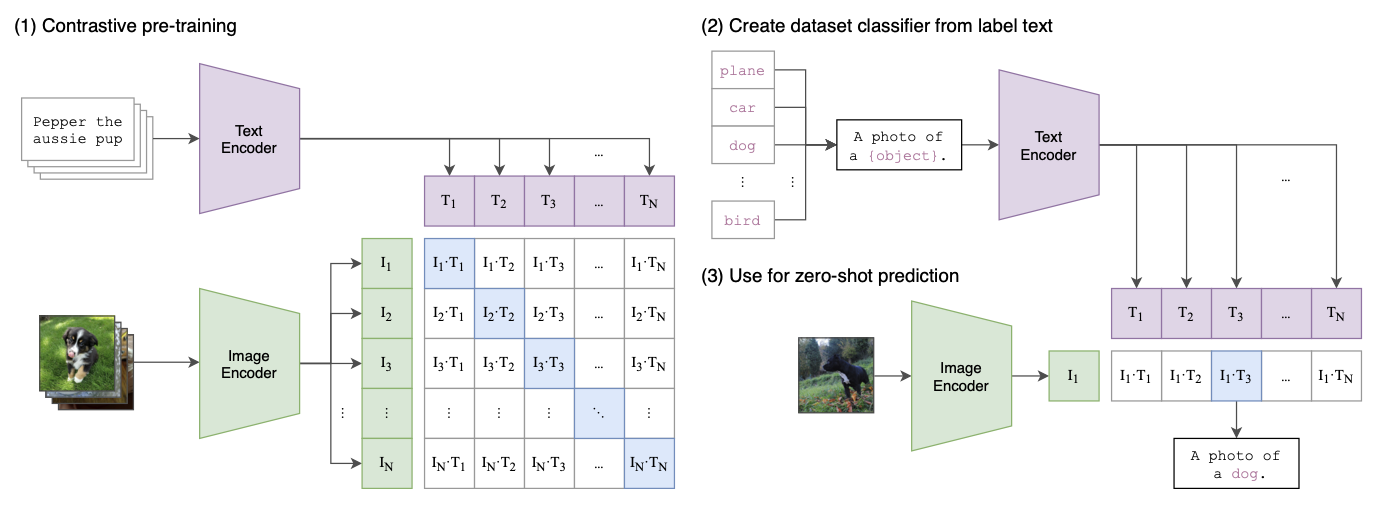
CLIP is a model that relates images to text via contrastive pre-training. Crucially, it embeds with images and text into a shared latent space that can be used for zero-shot tasks using unseen datasets.
Embeddings
Unlike other classification models, CLIP doesn’t associate images with a label. Rather, it’s fed image-text pairs from the internet where the text contains natural language (like sentences). Given these pairs, CLIP learns image and text encoders (a 🪜 ResNet or 🦿 Vision Transformer and a 🦾 Transformer, respectively) that map onto a shared latent space where the images and text from each pair have similar embeddings. These embeddings are incredibly valuable as they encode the fundamental meaning from both text and images, capturing both semantics and style; as such, CLIP encoders are used in many other works.
Contrastive Objective
To learn this latent representation and problem setup, we can’t use the standard predictive objective in classic methods—predicting the exact label from images. Instead, CLIP learns from contrastive pre-training, which aims to maximize the similarity between image and text embeddings from a pair while minimizing their similarity with other pairs. Specifically, it captures this with a symmetric cross entropy loss over cosine similarity.
Zero-Shot Transfer
With the pre-trained encoders, CLIP can adapt to any dataset distribution and label. For a given image and a set of possible text labels, CLIP simply predicts the label that has the highest similarity—crucially, the contrastive objective allows it to predict labels that it hasn’t even seen before.