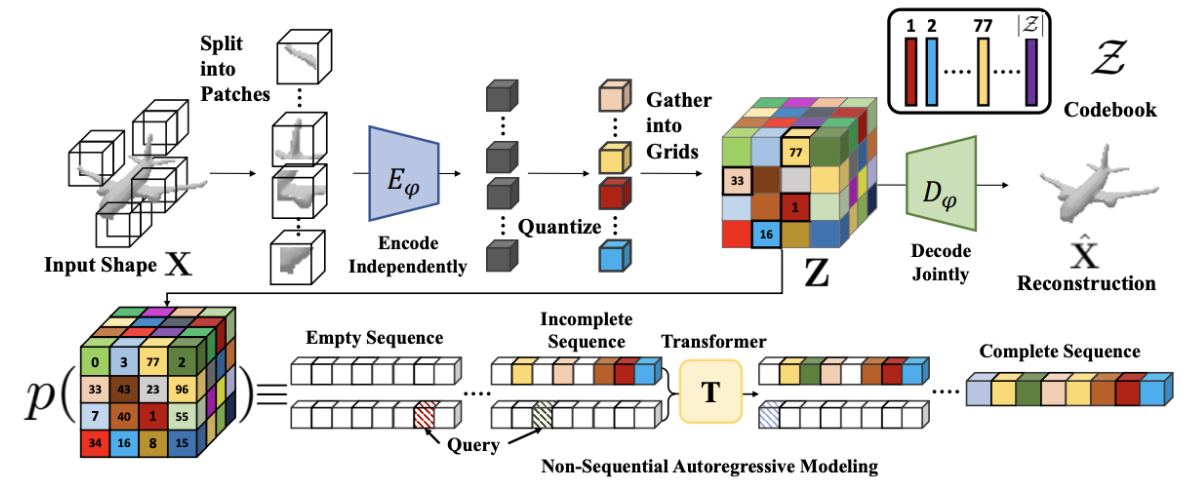
AutoSDF
AutoSDF first learns an encoding of complete models in a quantized latent space using 🔪 VQ-VAE with a patch-wise encoder and global decoder. This latent space distribution is then modeled by a non-sequential transformer—autoregressive modeling on randomized sequence orderings.
For conditional generation, we encode the input into partial latents, complete the sequence with our transformer, then decode with VAE.

SLIDE
Sparse latent point diffusion model (SLIDE) performs controlled mesh generation via two key observations:
- It’s much easier to generate point clouds first, then convert them to meshes.
- A dense point cloud can be generated in the latent space, then decoded.
Following these two ideas, SLIDE uses an encoder and decoder to convert between point clouds and a sparse latent point cloud representation; for reconstruction, the sparse latent point clouds go through diffusion to generate the full object.
The latent representation consists of “key” points, found via farthest point sampling, and their associated features that define the local geometric area. To diffuse a full shape, we train a DDPM to learn the latent point location and another DDPM to learn their features.

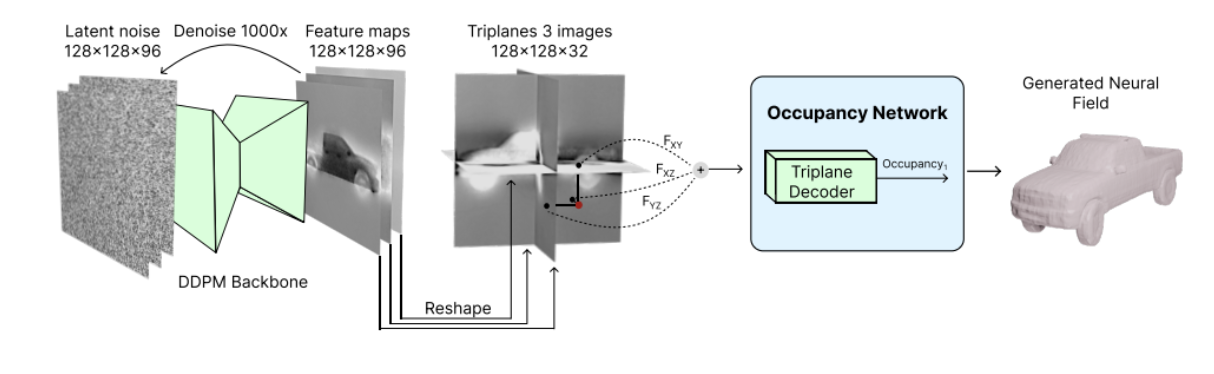
Triplane Diffusion
Triplane diffusion models a shared occupancy field that takes tri-plane projections as input,
These tri-planes and MLP
We can then train a 🕯️ Diffusion Probabilistic Model on the tri-plane features, which gives us shape generation.
ShapeFormer
ShapeFormer performs conditional generation by encoding points into a quantized sequence with an autoencoder called VQDIF, completes the sequence with transformer (predicting from scratch, conditioned on partials), and decodes into an occupancy field.
The VQDIF encoder converts the point cloud into a feature grid with local-pooled PointNet, flattens it into a sequence in row-major order, and compresses the features with vector quantization using a codebook. The decoder takes projects the sequence into the grid and decodes it into an occupancy network through a 3D U-Net.
