Distributed hash tables are very useful for storing key-value pairs. Much like a normal hash table, the key is hashed to a bucket, and the value is stored there (with chaining). To make this distributed, we have multiple machines, each responsible for some hash buckets.
Consistent Hashing
The set of servers holding hash buckets can be dynamic, causing potential data loss and changes to the number of buckets (which can depend on the number of servers). To support dynamic membership, we use consistent hashing: a method where the number of buckets stays constant, even if the number of machines changes. The key here is a decoupling of the hash entry with the node; we instead have a mapping that’s flexible to servers joining and leaving. For example, if the hash value is some integer in a bounded range, each server can have a unique ID within that range, and a hash entry to assigned to the smallest server with ID larger than its hash.
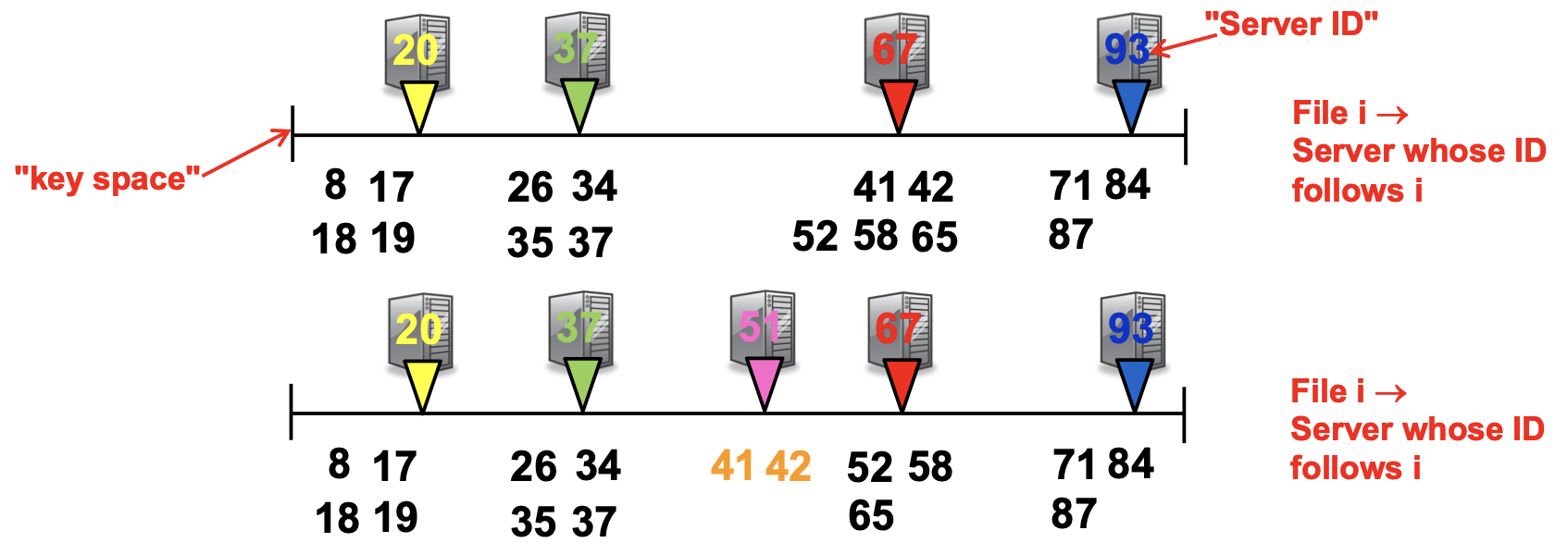
Key-Based Routing
For nodes in this system to communicate (for example, to get object with key