A cache is a hardware-managed collection of data built with SRAM that aims to make memory access faster and avoid bottlenecking the 🚗 Datapath.
Caches exploit two locality principles:
- Temporal locality: recently-referenced data is likely to be referenced again. Thus, we should cache recently-used data in a small and fast memory.
- Spatial locality: we’re more likely to reference data near recently-referenced data. Thus, we should cache large chunks to include nearby data.
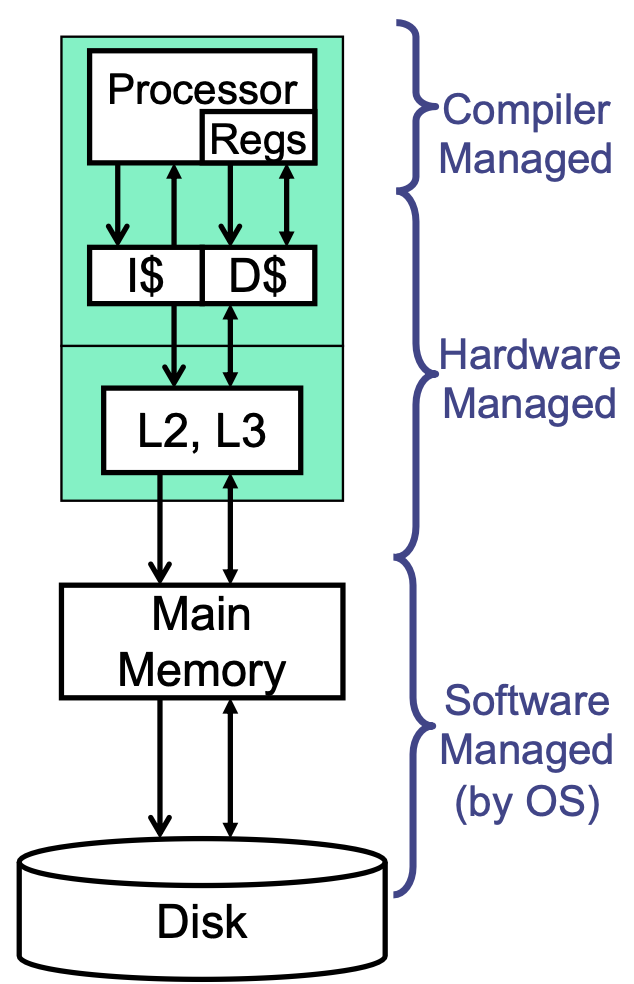
Hierarchy
In practice, we often use a hierarchy of caches. Caches closer to the CPU are smaller and faster, and caches farther away are larger and slower. Thus, upper components (I
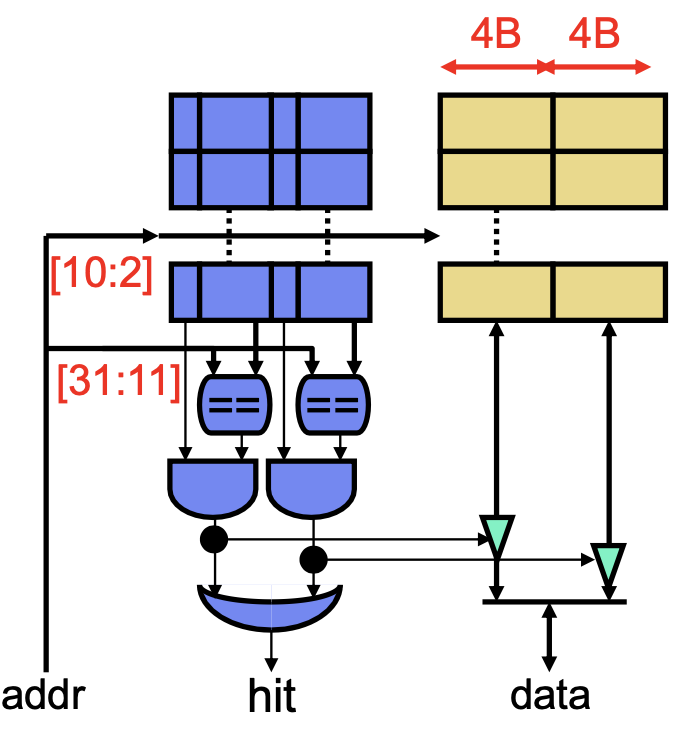
Cache Structure
A cache, at its core, is a hardware hashtable mapping memory addresses to blocks (also called lines). Concretely, we’ll use 10-bit address input and 4-byte/32-bit blocks; here, the 4-bytes is called the block size. For a 32-bit address, we use bits 11:2—index bits—to locate a block and bits 1:0—offset bits—to locate a specific byte within the block.
Multiple addresses can have the same index bits and map to the same block, so we need to keep a tag containing the remaining 31:12 bits for each block (plus a valid bit). To lookup a cache, we need to check if the tag matches and is valid, and if so, we can use the data in the block. To write, we need to first match the correct tag, then write to the block.
Read Miss
If the requested data isn’t in the cache, we need a cache controller (implemented as finite state machine) to perform a cache fill: remember miss address, access next level of memory, wait for response, and write response and tag to cache. These misses also stall the 🚗 Datapath pipeline (for instructions and data memory).
Write Miss
If the target block for a write isn’t in the cache, we have two options:
- Write-allocate: fill the block from next-level cache, then write it. This decreases read misses if we need this block again, but it requires additional bandwidth.
- Write-non-allocate: write directly to the next-level cache and don’t allocate a block.
Unlike a read miss, a write miss doesn’t need to stall the pipeline. Thus, we can keep a Store Buffer between the processor and cache: store instructions put the address and value in the buffer and continue, and the buffer actually writes stores in the background. This hides the effect of store misses.
Note that the Store Buffer causes consistency issues in 🍎 Multicore since it sits between the CPU and cache, so cache coherence doesn’t apply and a processor can’t see values in another processor’s Store Buffer.
Write Propagation
When we write to a cache, we need to choose whether to propagate this value to next-level cache or not:
- Write-through: propagate immediately.
- Write-back: propagate when block with the new value is replaced.
Write-Back Caching
Since write-back propagates sometime after the writes, there will be multiple versions of the same block within our hierarchy. To track the latest version and also know if write-back is necessary, we keep a dirty bit with the block that’s set if the block is written. During propagation, the dirty bit remains set, and it’s only cleared when the block goes into memory.
To hide the write-back latency, we can use a write-back buffer (WBB):
- Cache sends fill request for the replacement block to next-level cache.
- While waiting, cache writes dirty block to WBB.
- When the fill request’s block arrives, put it into cache.
- Write WBB contents to next-level cache.
Associativity
With the simple hashtable structure, two addresses with the same index bits will cause conflict. We can reorganize the cache with set-associativity: keep groups of frames (places to store blocks) called sets, and each frame in a set is called a way. Specific index bits correspond to a set, and the data can be stored in any way within that set; during lookup, we can check all of them in parallel, and any matched tag is a hit.
Replacement Policy
Now that we have multiple blocks in the set, which one should be replace during cache miss? This is decided by a replacement policy, which can be:
- FIFO: first in first out.
- LRU: least recently used, which aligns with temporal locality.
- NMRU: not most recently used, which is easier to implement than LRU.
- Belady’s: replace block that’s used furthest in future. Note that this is a theoretical optimum.
Performance
For a miss rate
Our goal is to make
- Increase cache capacity: this simply stores more data in the cache, so the miss rate decreases monotonically. However, this increases
latency. - Increase block size: this exploits spatial locality, changing the boundary between index and offset bits while keeping tag bits the same. However, this can cause potentially-useless data transfer and prematurely replace useful data, increasing conflict and capacity misses. Note that this also increases
, but we can largely avoid this effect for isolated misses by fetching the critical data first, continuing the pipeline, then filling in the rest in the background (called critical-word-first). - Increase associativity: this decreases conflict misses, which increases
(with diminishing returns) but increases .
Victim Buffer (VB)
Conflict misses occur if there’s not enough associativity, but high associative is expensive and rarely needed. We can have an additional component, called Victim Buffer, that’s a small fully-associative cache that provides a few extra ways shared by all sets, with the assumption that only a few sets need it at any given time. In practice, this is placed to catch instruction and data misses.
Prefetching
We can also bring data into cache speculatively, for example with the hardware anticipating a miss on the next block if the current block missed. This can also be done in software with a special prefetch instruction.