With Pipelining, we achieve pipeline-level parallelism where different stages run different instructions at the same time. The next level to this design is superscalar (also called multiple issue), with instruction-level parallelism: executing multiple independent instructions fully in parallel.
Key to this idea is having multiple instructions per stage (currently, around 2-6 is standard). An example ideal scenario is below:
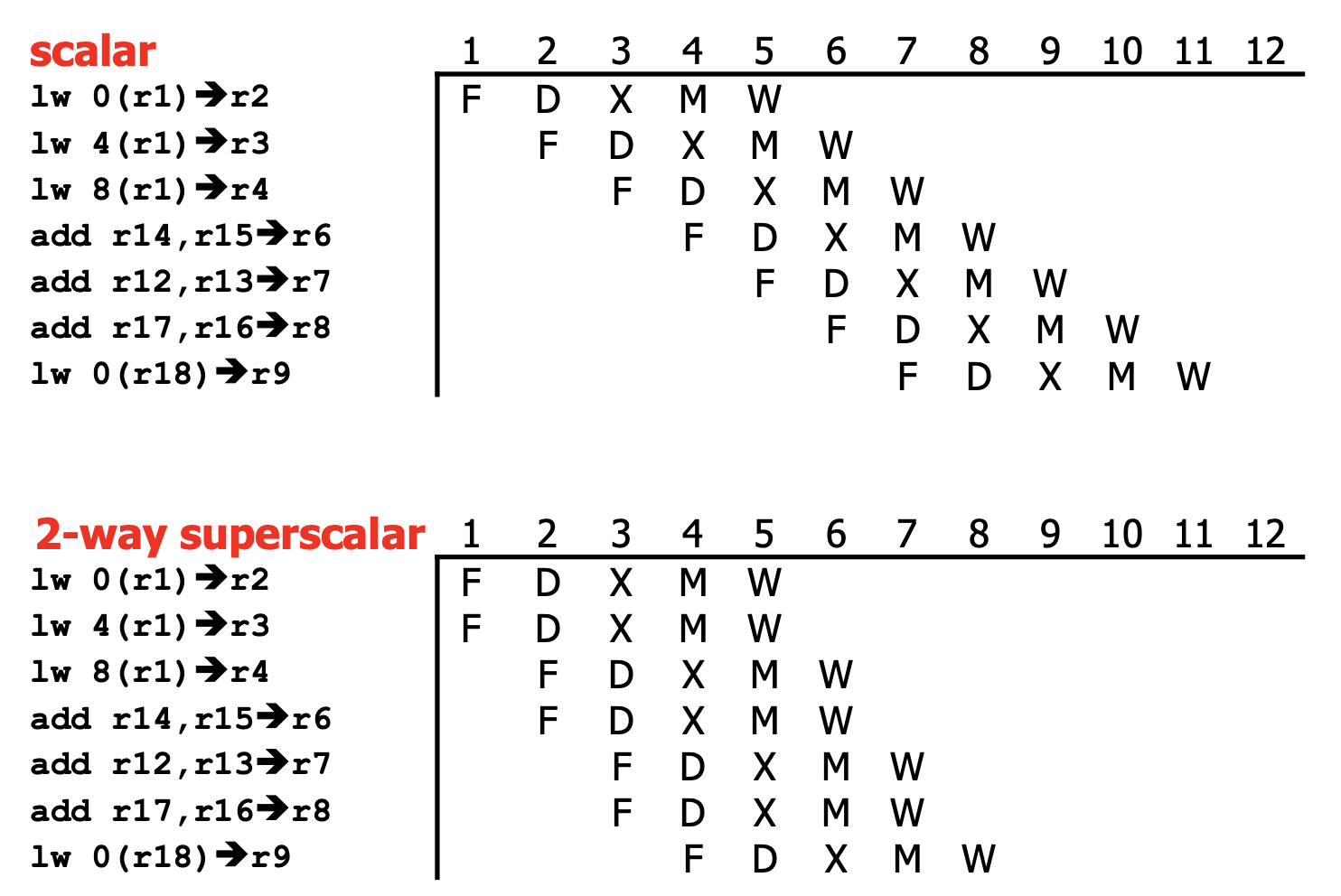
Realistically, there are still many dependencies, which limits the amount of instruction-level parallelism possible. It heavily depends on the application, even though the compiler tries to schedule code to avoid stalls.
Fetch
During fetch, we need to get multiple instructions per cycle. Complications arise when the next instruction is in another cache block, or when there’s branching. Below are two solutions:
- Over-fetch and buffer: add a queue between fetch and decode, and put instructions in the buffer. This compensates for cycles that fetch less instructions.
- Loop stream detector: if there’s a loop, put the entire body into a small cache.
Bypass
To implement bypassing for multiple parallel instructions, we need
To mitigate this
Register File
Another big